
Implement “Sleep” or “Wait” in WebMethods flow
I needed to send an external system a file import request. The external system would take some time to process […]
I needed to send an external system a file import request. The external system would take some time to process […]

In WebMethods, the most basic way to write a string “IN” operator is to use Branch as follows: Another way
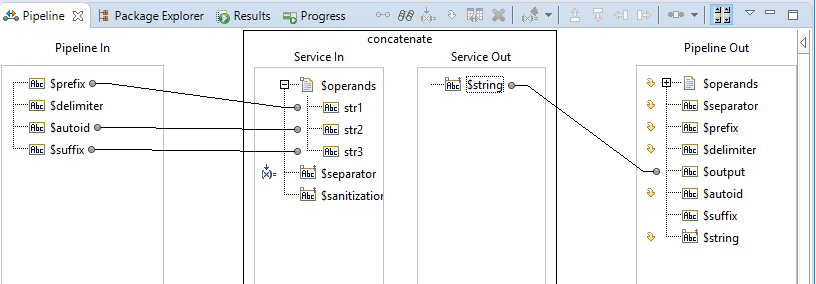
Manipulating string is probably the most frequent operation we need to do when transforming data. Thus, I’d like to talk
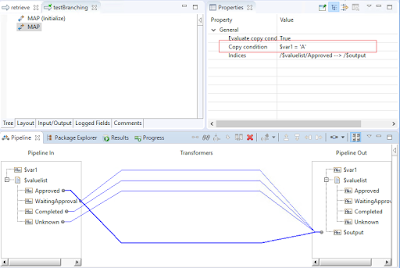
Conditional Logic is the most important building block of any software development tool. WebMethods is not a programming language, but