I often have to troubleshoot the issue of integration messages not getting processed. Most of the time, I got it right and was able to identify the problem quickly. In a few cases, it took some time and was stressful. These usually occur in Production. (They happen in DEV and PRE-PROD all the time, it’s just that people usually don’t care, and it goes unnoticed)
Today I had to deal with it again and it took me some time. The cause was something I dealt with before and I was told by a colleague how to fix it the easy way, but I forgot. This time around, under the panic mode, I restarted a few JVMs before I remembered I should ask around and was reminded by my colleague again that it could be fixed with much less damage. I told myself I should write it down for the next time
Below are the notes on what I learned:
Publish Channel in Maximo uses Sequential Queue by default. When a message fails, it will stop processing other messages.
In some systems, the behaviour (Sequential processing) can be disabled by simply changing the error output of SQOUTBD bus destination from “none” to “system” or an error queue.
Check Message Tracking to see if there are messages stuck in “RECEIVED” status. If there are many of those messages. it means JMSConsumer doesn’t run, or it does run but one message failed (has ERROR status in Message Reprocessing), and thus everything else got stuck. If there is no message in “RECEIVED” status, it is either because Publish Channel is not enabled, or because Message Tracking is not enabled.
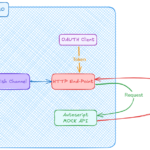
For Publish Channel to publish messages, we need both the External System and the Publish Channel to be enabled. Event Listener on the Publish Channel should be enabled (unless it is triggered by something else like an Autoscript)
If Message Tracking is not enabled for the Publish Channel, we should enable it (now), unless the interface is extremely unimportant, and no one cares.
If there are a ton of “RECEIVED” messages in Message Tracking, it’s likely due to two reasons noted below. Messages that get published successfully have “PROCESSED” status.
If there’s an error in Message Reprocessing that blocks the queue, try to re-process, or delete it to clear the blockage.
If there’s no blockage in Message Reprocessing, it’s likely due to JmsConsumer cron task not running. Try reactivating/reloading the cron instance. Make sure to enable the “Keep History?” flag. After re-activating and reloading the cron instance. If it shows “START”, but doesn’t show “ACTION”, it means the Cron instance doesn’t run. It’s likely there’s a hang scheduler task. It can be resolved by restarting the concerned JVM/server. This is the bad approach used today. The easy way is to query and delete the task entry in “TASKSCHEDULER” table. Don’t worry, once deleted, the cron task instance will create a new task entry on the next run
For blockage on sequential queue, on a non-prod environment, we can see queue depth and clear all of those messages in the queue to clear the blockage using two methods below:
In Maximo, go to External Systems > Action Add/Modify Queues > Select “sqout” > choose View (or Delete Queue Data)
In Websphere, go to Service Integration > Buses > Destinations > SQOUTBD > Queue Points. It will show Queue Depth which is the number of messages in the queue. Click on the link to open > Runtime tab > Messages > Delete or Delete All
When writing a piece of software, we are in total control of the quality of the product. With integration, many elements are not under our control. Network and firewall are usually managed by IT. With external systems, we usually don’t know how they work, or many times, not given access. Yet, any changes to these elements can cause our interfaces to fail.
For synchronous interfaces, the user would receive instant feedback after each action is taken (e.g. Maximo GIS integration), we don’t usually need to set up alarms. For asynchronous interfaces, which don’t give instant feedback, when failure occurs, it usually goes unnoticed. In many cases, we only find out about failures after it has caused some major problem.
A good interface must provide an adequate ability to handle failures, and in the case of async integration, proper alarms and reports should be set up so that failures are captured and handled proactively by the system administrators.
On the one hand, it is bad to have no monitoring. On the other hand, way too much alarm is even worse. It leads to the receivers of these alarms completely ignore them including the critical issues. This is usually seen in larger organisations. Many readers of this blog won’t be surprised when they open the Message Reprocessing app and find thousands of unprocessed errors in there. It’s likely that those issues have been accumulated and not dealt with for years.
It is hard to create a perfect design from day one and build an interface that works well in the first release. There are many kinds of problems an external system can throw at us, and it is not easy to envision all possible failure scenarios. As such, we should expect and plan for an intensive monitoring and stabilizing period of one to a few weeks after the first release.
As a rule of thumb, an interface should always be monitored and raise alarms when a failure occurs. It should also allow resubmission or reprocessing of a failed message. More importantly, there shouldn’t be more than a few alarms raised per day on average from each interface, no matter how critical and high volume it is. If there are more than a few alarms per day, it will become too noisy, and people will start ignoring them. In that case, there must be some recurring patterns and each of them must be treated as a systemic issue. The interface should be rebuilt or updated to handle these recurring issues.
It is easier said than done, and every interface is a continuous learning and improvement process for me. Below are some examples of the interfaces I built or dealt with recently. I hope you find it entertaining to read.
Case #1: Integration of Intelligent Transport System to Maximo
An infrastructure construction company built and is now operating a freeway in Sydney. They use Maximo to manage maintenance works on civil infrastructure assets. An external provider (Kapsch) provided toll point equipment and a traffic monitoring system. Device status and maintenance work from this system are exported daily as CSV files and sent to Maximo via SFTP. On the Maximo side, the CSV files are imported using a few automation scripts triggered by a cron task.
The main goal of the interface is to maintain a consolidated database of all assets and maintenance activities in Maximo. It is a non-critical integration because even if it stops working for a day or two, it won’t cause a business disruption. However, occasionally, Kapsch stopped exporting CSV files for various reasons. The problem was only found out after a while, like when someone tried to look up a work order but couldn’t find it, or when a month-end report looked off. Since we didn’t have any access to the traffic monitoring system managed by Kaspch, Maximo had to handle the monitoring and alarms of this integration.
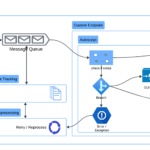
In this case, the difficulty is, when the interface on Kapsch’s side fails, it doesn’t send Maximo anything, there would be no import, and thus no errors or faults seen by Maximo to raise any alarm. The solution we came up with is having a custom logging table in which we write each import as an entry with some basic statistics including import start time, end time, total records processed and the number of records that failed. The statistics are displayed on the Start Center.
For alarm, since this integration is non-critical, an escalation is set to monitor whether there has been no new import within the last 24 hours, Maximo will send out an email to me and the people involved. There are actually a few different interfaces in this integration, such as for device list and preventive maintenance work coming from TrafficCom, or corrective work on faults coming from JIRA. Thus, sometimes, when a system stopped running for various planned or unplanned reasons, I would receive multiple emails for a couple of days in a row, which is too much. So, I tweaked it even further by sending only one email on the first day if one or more interfaces stopped working, and another email reminding me a week later if the issue had not been rectified. After the initial finetuning period, the support team on Kapsch and Maximo’s side is added to the recipient list, and after almost two years now, the integration has been running satisfactorily. In other words, there have been a few times files were not received on the Maximo side and the support people involved were always informed and able to take corrective action in a timely manner before the end-users could notice.
Case #2: Integration of CRM and Maximo
A water utility in Queensland uses Maximo for managing infrastructure assets, tracking, and dispatching work to field crews. When a customer calls up requesting a new connection or reporting a problem, the details are entered to a CRM system by the company’s call centre. The request will then be sent to Maximo as a new SR, and then turned into work orders. When the work order is scheduled and a crew has been dispatched, these status updates are sent back to CRM. At any time, if the customer calls up to check on the status of the request, the call centre should be able to provide an answer by looking up the details of the ticket in CRM only. Certain types of problems have high priority such as major leaks or water quality issues. Some issues have SLA with response time in minutes. As such, this integration is highly critical.
WebMethods is used as a middleware to handle this integration, and as part of the steps for sending new SR from CRM to Maximo, the service address will also need to be cross-checked with ArcGIS for verification and standardization. As you can see, there are multiple points of failure with this integration.
This integration was built several years ago and there has been some level of alarms set up in CRM on a few points where there is a high risk of failure such as when a Service Order is created but not picked up by WebMehods or picked up but not sent to Maximo. Despite this, the interface would have some issues every few weeks, and thus, needed to be rebuilt. In addition to existing alarms coming from CRM, several new alarm points were added in Maximo and Webmethods:
When WM couldn’t talk with CRM to retrieve a new Service Order
When WM couldn’t send a status update back to CRM
When WM couldn’t talk to Maximo
When Maximo couldn’t publish messages to WM
These apply to individual messages coming in and out of Maximo and CRM and any failure would result in an email sent to the developer and the support team.
In the first few days after this new interface was released to Production, the team received a few hundred alarms each day. My capacity to troubleshoot was about a dozen of those alarms a day. Thus, instead of trying to solve them. We tried to identify all recurring patterns of issues and address them by modifying the interface design, and business process, or fixing bad data. A great deal of time was also spent on trying to improve the alarms, such as for each type of issue, detailed error messages, or in many cases, the content of the XML message itself is attached to the email alarm. A new “fix patch” was released to Production about two weeks after the first release, and after that, the integration only produced a few alarms per month. In most cases, the support person can immediately tell what the cause of the problem is by just looking at the email before even logging in to the client’s environment. After a year now, all the possible failure points that we envision, no matter how low of a chance it can occur, have failed, and raised alarms at least once, and the support team has always been on top of it. I’m glad that we had put in all those monitoring in the first place. And as a result, I haven’t heard of any issues that have not been fixed before the end-users become aware of it.
Case #3: Interface with medium criticality/frequency
Of the two examples above, one is low frequency/low criticality; the other is high frequency and high criticality. Most interfaces are somewhere in the middle of that spectrum. Those interfaces that are highly critical but don’t run frequently or don’t need short response time can also be put into this category. In such cases, we might not need to send individual alarms in realtime. Even an experienced developer cannot troubleshoot more than a few issues per day. As a rule of thumb is, if an interface raises a few alarms per day, it is too much. As developers, if we can’t handle more than a few alarms a day, we shouldn’t do that to the support team (sending them alarms all day long). For the utility company mentioned above, when WebMethods was first deployed, the WM developer configured a bi-daily report that lists all failed transactions that occurred in the last 12 hours. Thus, for most interfaces, we don’t need to set up any specific alarms. If there are a few failures, they will show up in the report and will be looked at by technical support at noon or at the end of the day. This appears to work well, even for some critical interfaces such as bank transfer orders or invoice payments.
Case #4: Recurring failure resulting in too much alarm
For the integration mentioned in #1 and #2, the key to getting them to work satisfactorily is to spend some time after the first release to monitor the interfaces and finetune both the interface itself and the alarms. It is important to have alarms raised when failure occurs, but it is also important to ensure there aren’t too many alarms raised. Not only people will ignore it if they receive too many alarms, it also makes it hard to tell the critical issues apart from other less important ones. From my experience, dealing with those noisy alarms is easy. Most of the time, the alarms come from a few recurring failures. When people first look at it, they can easily be overwhelmed by the high number of issues and feel reluctant to deal with it. The strategy is simply deal with each alarm/failure one by one, and carefully document the error and the solution for each problem on an Excel spreadsheet. Usually, after going through a few issues, a few recurring patterns can be identified. By addressing them
Example: a water utility in Melbourne uses an external asset register system, and the asset data is synchronized to Maximo in near realtime. The interface produces almost 1GB of SystemOut.log file each day causing the logs to be useless. I looked at each error and documented them one by one. After about two hours, it was clear that 80% of the errors came from locations missing in Maximo. When the interface creates new assets under these locations, Maximo produces a lot of error trace to SystemOut log file. I did a quick scan and wrote down all of the missing locations and quickly added them to Maximo using MXLoader. After that, the amount of error was reduced significantly. By doing occasional checks on the log files in the following few days, I was able to list all missing locations (there were about 30 of them) and able to remove all errors caused by this. The remaining errors found in the log files were easily handled separately. Some critical issues only came under the radar of the business after that.
The standard way to send a message from Maximo to an external system is by setting up a Publish Channel and enabling Event Listener. By default, Integration Framework doesn’t re-publish a change if it comes from another inbound interface to prevent recursion on a bi-directional interface. Although I don’t agree with this logic because one-way integration is much more common, IBM said it is easy to override that by extending the Event Filter java class.
The problem is, with the rise of automation script, Java customization is not preferable. Of course, for massive systems where performance is critical, it is still the best choice. However, for most medium-sized clients I work with, they’re all moving away from Java customization.
Anyway, an approach we can deal with this issue is do not use Event Listener at all. Instead, we can trigger a publish from an Object Save launch point from automation script using the example python code below:
Working with Maximo, we have to deal with network/firewall all the time. I can spend a whole day telling you fun stories (or extremely frustrating experience) I had with IT/Network guys. But that’s not the point. If you end up here, I guess you’re having an issue with firewall. So below is a quick recap of my tricks:
– Ping: the first thing we try when we want to see if a server is accessible from our current machine. But don’t jump to a conclusion too early if it shows the server is unreachable. Sometimes, the Network Admin has disabled ping response to enhance security.
– Telnet: to check if a port is opened, we can use telnet from Windows Command console (e.g. telnet google.com 80). If it can be connected, means the target server is accessible on the specified port. But if it doesn’t, first, make sure the server is listening on that port, before jumping to a conclusion that it’s a Firewall issue. I made this mistake a few times, blaming the network, then it turned out it’s Websphere/Maximo service is not running on the port that I assumed it should be running on
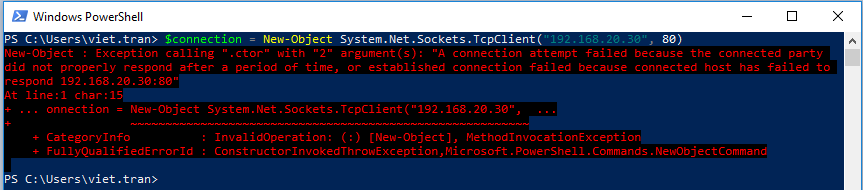
– PowerShell: in many cases, the server is not connected to the Internet, and Telnet is not installed, (and yes, you don’t have permission to install new software either). We can use PowerShell to check network connectivity using the two commands below:
For many organisations, when starting a mobile project, the stakeholders may not have prior experience with mobility solutions for EAM. As such, we are sometimes asked to implement features that do not add much value to the business. As consultants, it is satisfying to see something we implement being used and helps the end-users on the field. And nothing can be more frustrating than spending time building features that are not going to be used. In this post, I will talk about some commonly used and not used functions of a mobile app.
Work Execution
Despite its name is Asset Management software, 80% of activities in Maximo happen around the Work Management process. It is not a surprise work execution is the number one use-case for a mobile app. However, work management is a big process with a few major stages and many different activities. Only certain activities need to be recorded in the field with a mobile device. Below are some common ones:
Change Work Order status: start work, put it on hold, or complete the work
Record actual costs: travel time, work time, material consumption
Capture and attach photos
Enter work log
Capture operational parameter (meter reading)
By having a mobile device to capture these data on the field as it happens, organizations benefit from having much more accurate data. The last one is a key enabler for a comprehensive Condition Monitoring program which is an important topic and I’ll cover it in a separate post.
Physical Signature
The ability to physically sign on a mobile device sounds great. Most mobile apps has this function. I have implemented this a few times. The user can physically sign on a mobile device. The signature is printed at the bottom of some BIRT reports (e.g. Work Completion form or Risk Assessment form etc.). It looked great and the customers were excited about it. But in all honesty, I find it’s not really an important feature.
Work Planning and Approval
These are the activities that can and often be done in an office setting with the user accessing Maximo using a browser. The planning process can involve 3rd party scheduling tools like Akwire, Primavera, Visual Planner etc. Who would want to go to the field to schedule and assign people to some work orders on a tiny mobile screen? Some mobile apps do have the capability to do that, but it doesn’t mean we have to use it. These features are available usually for the field user to see the planned information, and possibly edit some incorrect details.
Inspection Form
Inspection Form was introduced from Maximo 7.6.0.8 as part of the Work Center module, and progressively improved in the last few releases. This is the best feature among those added to Maximo for the last 10 years. However, the Work Center interface is still too limited to be practical (UI is too slow, requires stable and fast connectivity, and not customizable).
EzMaxMobile does the job very well by providing responsive online and offline UI and works well with the out-of-the-box backend in Maximo. From my limited knowledge, Datasplice had Inspection app since at least a few years back, long before Maximo. That is because Datasplice is an independent system with its own database. There are inspection mobile solutions provided by industrial vendors too (e.g. Honeywell).
I don’t know how well these solutions work. My point is this is a common requirement and haven’t been addressed by Maximo until recently. By filling out inspection forms on a mobile device, data is fed directly to the meter reading tables. With this, condition monitoring can be setup in Maximo which raises alarms or PM work orders automatically.
Inventory Count / Stocktake
My first three mobile projects were to address this requirement, so, it must be a good use-case. The task is simple: the user scans a barcode, enters a balance value, then saves. Extended features could be adding a photo of the item, adding a new bin, or updating item specification which later can be used for the cataloguing and de-duplication process. The key to getting it to work is a really smooth and efficient user experience as these steps need to be repeated a thousand times in one shift. Fast and simple UI running in full offline mode is a must.
Me counting and capturing item spec at a time mobile solution wasn’t available. All data needed to be manually entered into Maximo by some interns later on
Inventory Issue/Transfer/Receipt
I’ve seen some projects involved these apps. In general, how often it is used and how much value it brings to the organization is not known to me. I think it does add value, but of course, not at the level of the Point-of-Sales solutions we often see in a supermarket.
Purchase Requisition/Purchase Order
Although PR and PO apps are available on some mobile solutions, I haven’t seen them used anywhere. There is some value for the field workers to be able to create Requisition. That function belongs to the Work Order module though. The data then flows to the PR application and handled by the backoffice staffs with a computer and a browser.
Risk Assessment/Toolbox Talk
This is a great use case for a mobile app. It is something that must be done on the field, it adds a lot of value in term of safety improvement and compliance. In many cases, it has some legal implication. Unfortunately, even the Oil & Gas (HSE) module in Maximo does not meet all of the requirement and usually needs a lot of customization. We had implemented this feature in EzMaxMobile for some clients. But the assessment forms and the compliance requirements are different in each industry and from company to company. Thus, I don’t think we can see a standard risk assessment mobile app for Maximo anytime soon. If your company needs it, you may have to pay for the customization effort.
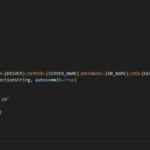
I had to look at an existing interface in Maximo production which publishes data outbound. The interface is working well but we don’t have any documentation. I like to use POSTMAN to send some test requests to figure out how the API works. Unfortunately, password for the API is kept in a System Properties and is masked and encrypted.
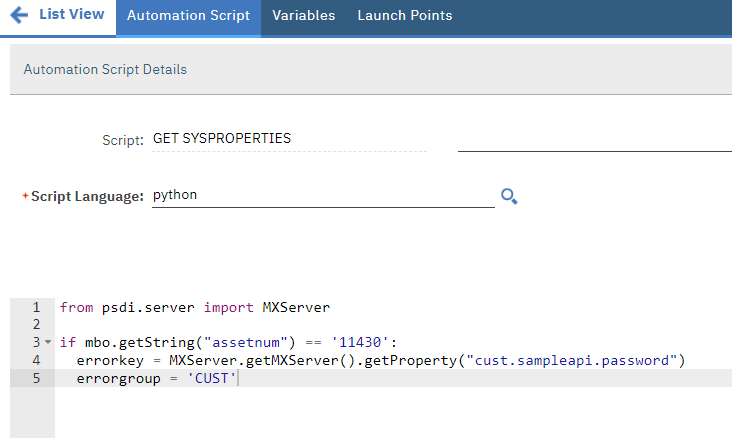
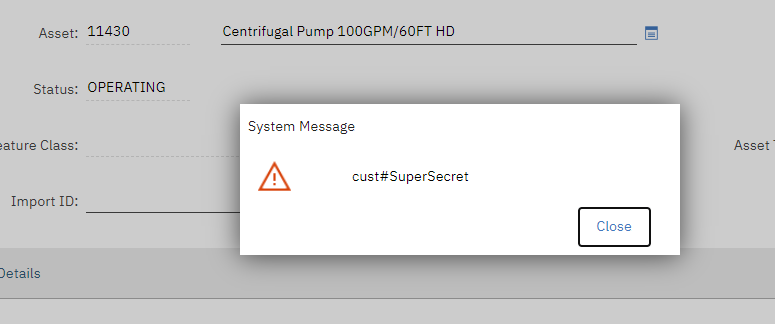
I struggled for a while until I realized, since System Properties are meant to be accessible by code, it means, I can easily retrieve and display the value from code. So, I created an automation script on the Save event of the ASSET object to display the value:
The code has a filter on a specific asset to minimize the chance it can cause trouble to end users who might update Asset data while I’m doing this. This is my favorite approach when I want to run some code on production.
I am a freelance Maximo consultant based in Melbourne. If you enjoy reading my blog, please connect with me on LinkedIn to get updates on new posts. If you or your company need any professional assistance, please leave me a message, I'll call you back.