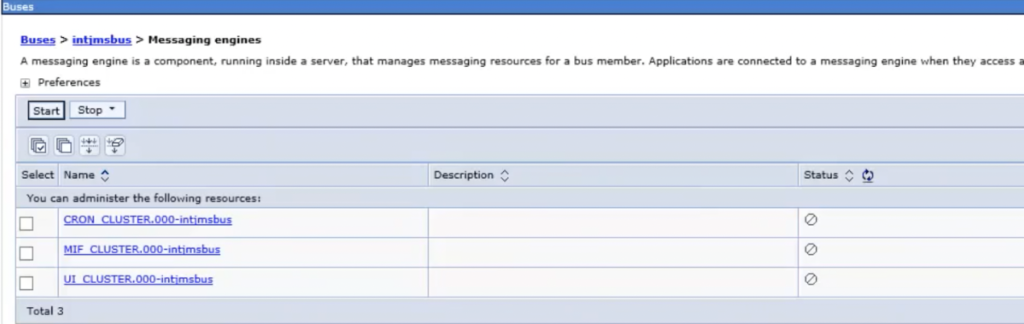
Message Engine doesn’t start after setting up cluster
This issue hit me a few times and always took me some time to figure out what happened. So I […]
This issue hit me a few times and always took me some time to figure out what happened. So I […]
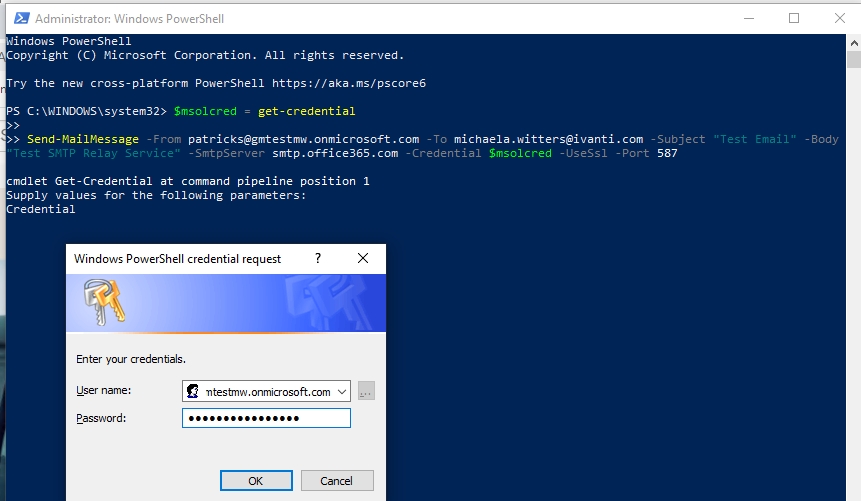
In an enterprise IT environment, setting up Maximo to talk with SMTP service is sometimes difficult due to networking and
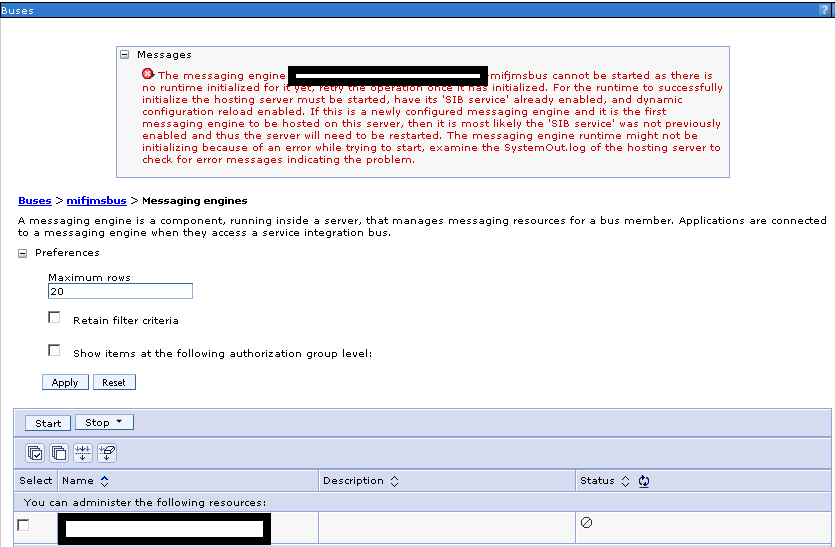
I sometimes have issues with message engine not running. Usually I’ll just try to restart the whole system and hope

This post describes the simplest approach on how to post HTTP request from Maximo Automation Script using a HTTP End Point
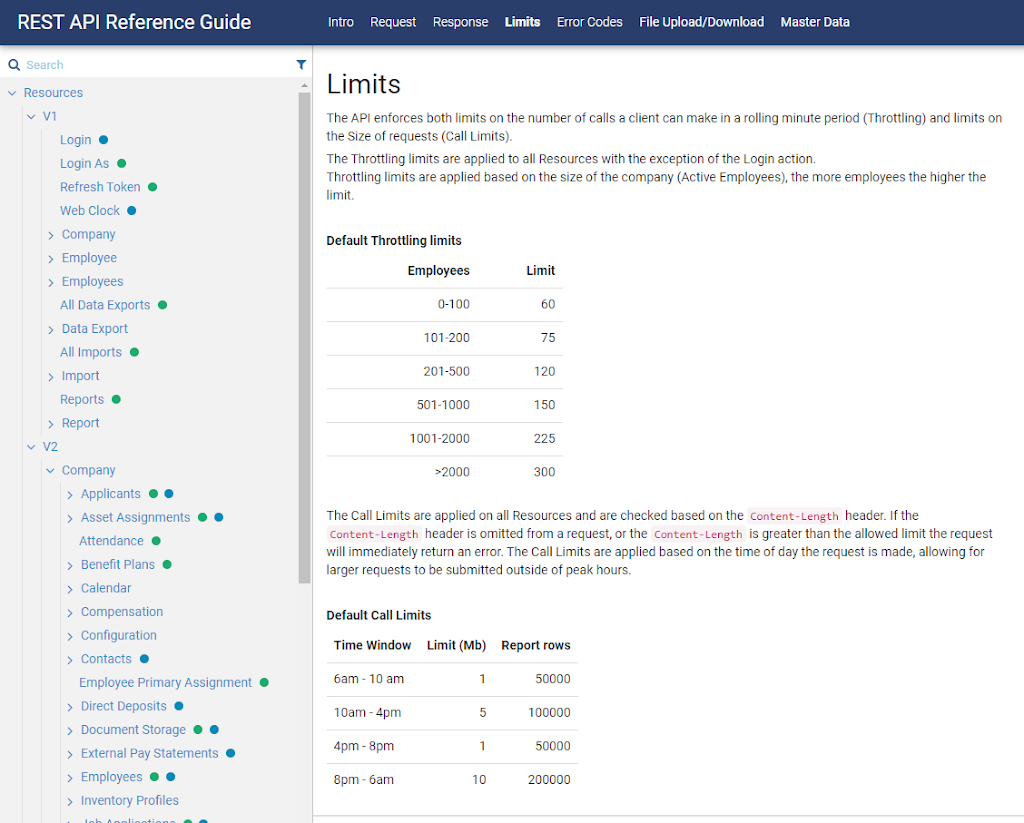
For integration with Kronos, I would look at the Report API and the Import API first. I will only go for the REST API if they cannot do what I want

I often have to troubleshoot the issue of integration messages not getting processed. Most of the time, I got it
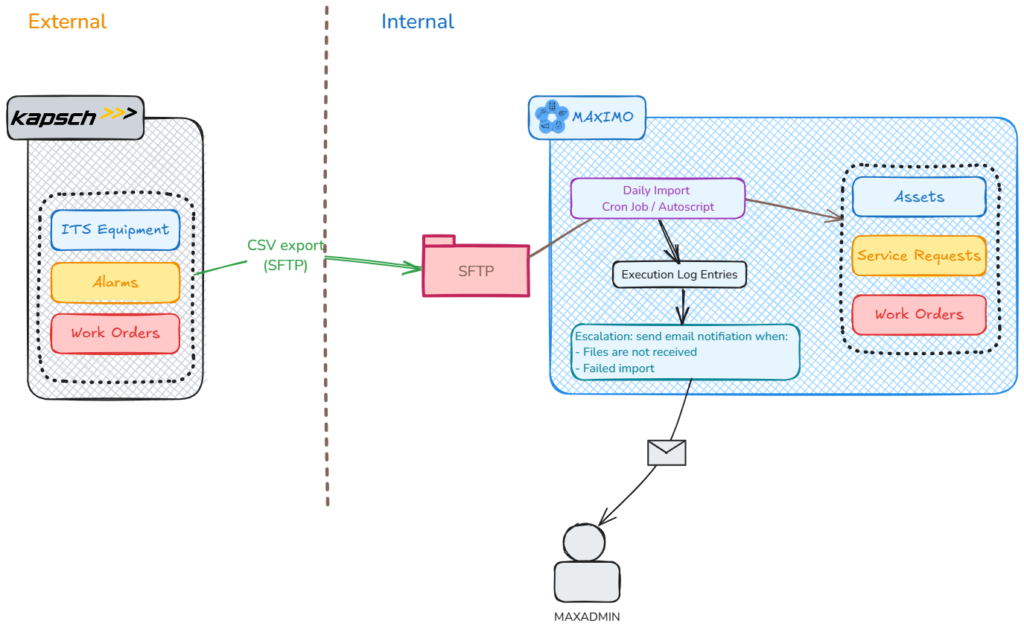
Introduction When building an application, we are in total control of the quality of the product. With integration, many elements
The standard way to send a message from Maximo to an external system is by setting up a Publish Channel
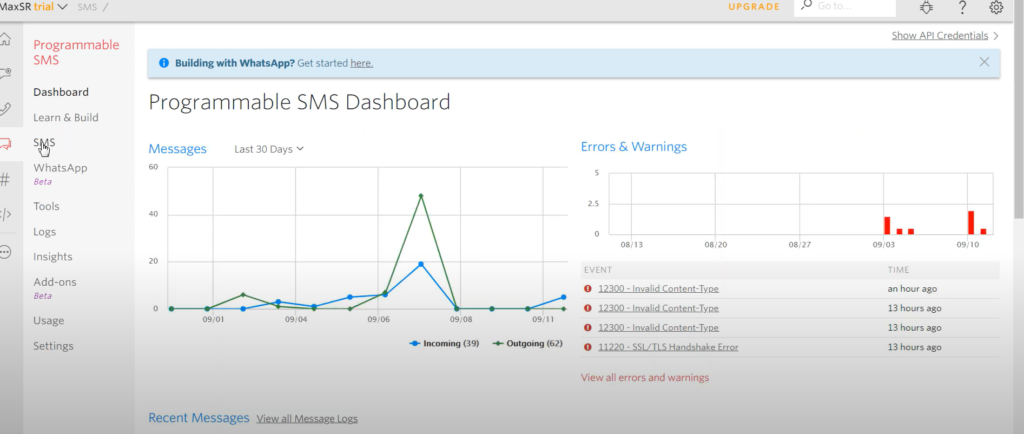
In my previous post, I provided some demos on how we can process inbound text messages to create SR and