Last week, I played around with Oracle’s new toy: the InMemory feature available in Enterprise Edition. Although it made Maximo runs 1.25x faster, but it didn’t meet my expectation which was from 2x to 5x. This has bothered me for the whole week and I kept thinking about it.
If you’ve read my previous blog post, the one thing I pointed out which could lead to no performance improvement is that I ran the test on a tiny demo version. It has only a few hundred assets and less than a thousand work orders. So, any heavy processes or poorly written queries couldn’t make the database 1 second slower. This week, I set out to do a more elaborate test with a setting that looks more similar to a real production environment.
At first, I setup my system as follows:
- For Maximo: v7.5 with several industry solutions and add-ons. The data includes 4M work order records, 200k Assets & Locations, 200k Issue Transactions, and 1M Labor Transactions. Total size of the DB is more than 50GB.
- For DB Server:
- HP EliteBook 840: Core i7-6600U 2.7 Ghz, 16GB RAM, SSD 512.
- Oracle 12c Enterprise: 3GB allocated to PGA, 11 GB allocated to SGA (which includes 6GB allocated to InMemory data store)
- For App Server: Virtual Box running on Mac OS host: Core i5 2.3 GHz, 16GB RAM, SSD 512GB
- VBox configuration: Windows 2012 x64, 12GB RAM
- Websphere: Cluster with 3 JVMs x 3GB each.
I got one problem though. The two machines connected wirelessly to each other via a home wifi router which gave a latency of between 5ms to 20ms, sometimes it went up to 100ms or even timeout. This resulted in the system ran with unpredictable performance. In practice, network connection between Application Server and DB Server usually have a latency of < 1 ms. So I abandoned the idea of having the system runs on two separate boxes, and returned to a configuration with everything runs on one laptop as follows:
- Database: PGA – 3G, SGA – 8G (5G of which is InMemory)
- Only one MXServer JVM with 3 GB
I intended to test and compare following operations:
- Run a Saved Query on Work Order Tracking app
- Generate 7 PM Work orders at once
- Change status of 27 Work orders at once
- Run a simple Report created by “Create Report function” which joins two tables: Work Order and Asset
- Run a more complex report which joins a few tables including Work Order and Actual Labor and Actual Material
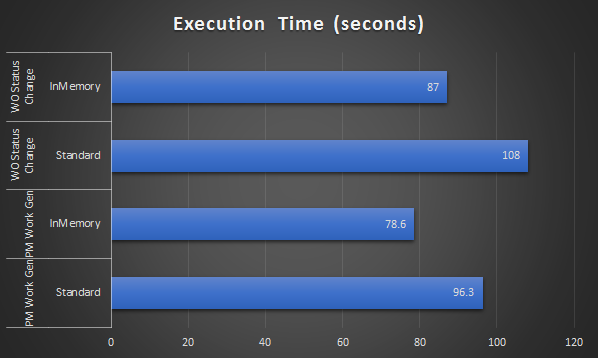
For each of the operations above, I ran test three times to get the average execution time (I ignored the first run as it is usually longer since data hasn’t been populated and cached to memory yet). Below is the result:
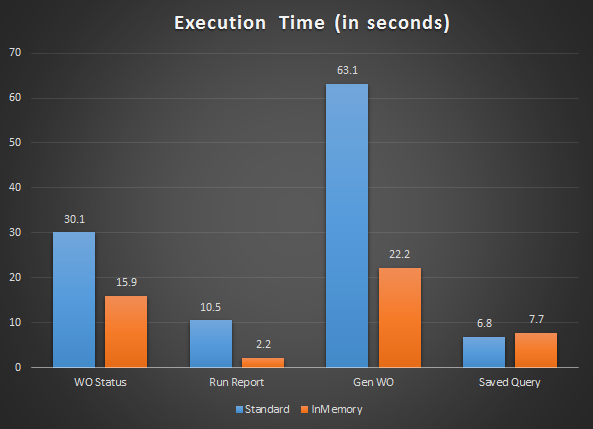
For the running saved query, I don’t understand why it took longer to load (result was consistent, not random)
For other expensive operations, Maximo ran 2-3 times faster.
For the more complex report, it never finishes. I tried several times and with the longest one I waited for 50 minutes before killing the process (I checked and Oracle was still processing, not hang). Even after turning on InMemory, it took more than 20 minutes, then I killed it as I was too tired to wait.
For the simple report, it is 5 times faster. If we pay close attention here, the BIRT report window took more than a second to open already, which means DB query returned result almost instantly. This made me believe that we could get a 10-15x performance gain for reports that take several minutes to run.
Since I had to abandon my original setting with two laptops, and also, because I was too lazy to build a new report which will take around 5-20 minutes to run on this environment, I couldn’t test a heavier load scenario with several expensive read/write operations like PM Gen, WO Change Status, and running several slow reports at once. This kind of load is what we normally see in production and usually slow down the system significantly because operations and queries have to wait for each other to release resource lock. But this situation is exactly where InMemory will make a huge difference.
Anyway, even with this result, I am happy, and from now on, I will be all out selling “memory upgrade” to whomever Maximo users I meet.
An afterthought note: I used to consider DB2 a second choice for Maximo due to the difficulty of finding a good DB2 DBA, and thus, usually only suggested it to small clients with low budget. But now considering the significant cost of Enterprise version of Oracle or SQL if users want to implement this feature, the free bundled DB2 license offered with Maximo is an attractive option. For large enterprise client, I guess I will now present DB2 as an option for them to consider too.