Ever since ChatGPT’s release, I’ve been contemplating how to leverage large language models (LLM) to enhance legacy applications like Maximo. Given the ability to engage in a conversation with the machine, an obvious application is to facilitate easy access to information through semantic search in the Q&A format. To allow a generic LLM model to respond to inquiries about proprietary data, my initial thought is fine-tuning. However, this approach comes with several challenges including complexity and cost.
A more practical approach is to index organisational data and store it in a vector database. For instance, attachments (doclinks) can be divided into chunks, indexed, and kept in a vector database. When asked a question, the application would retrieve the most relevant pieces of information and feed them to an LLM as context. This enables the model to provide answers with actual details obtained from the application. The key advantages of this approach include:
- Low cost
- Realtime data access
- Traceability
Last month, OpenAI introduced the function calling feature to its API, providing ChatGPT with an additional mean of accessing application data. By furnishing it with a list of callable functions, ChatGPT can determine whether to answer a question directly or execute a function to retrieve relevant data before responding. This powerful feature has generated some buzz among the development community. After trying it out, I was too excited to ignore it. As a result, I developed an experimental Chrome extension that enables us to talk with Maximo. If you’d like to give it a try, you can find it on the Chrome Web Store under the name MaxQA.
How it works:
- This tool is purely client-based, meaning there is no server involved. It directly talks with Maximo and OpenAI. To use it, you will need to provide your own OpenAI API key.
- I have defined several basic functions that OpenAI can call. They work with Maximo out of the box.
- You can define new functions or customize existing ones to allow it to answer questions specific to your Maximo instance. To do this, right-click on the extension’s icon and open the extension’s Options page.

- The app uses OpenAI’s “gpt-3.5-turbo-0613” model, which is essentially Chat GPT 3.5. As a result, you can ask it any questions. For general inquiries, it will respond like ChatGPT 3.5. However, if you ask a Maximo-specific question, OpenAI will direct the app to execute the appropriate function and provide the necessary input parameters. The data response from Maximo will be fed back to OpenAI, which will then generate an answer based on that data.
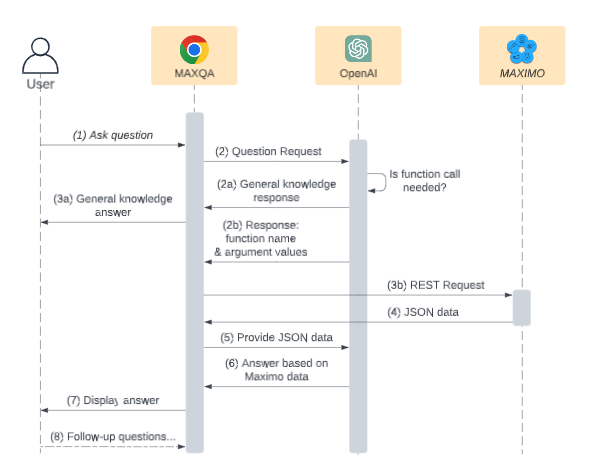
Through this exercise, I have gained a few insights:
- Hallucination: while the inclusion of actual data reduces the likelihood of hallucination, there are still occasional instances where it provides convincing false answers. We can address this with prompting techniques such as instructing it to not make up an answer if it does not know the answer. Nonetheless, this remains an unsolved problem with this new technology.
- Fuzzy logic: consistent formatting of answers is not guaranteed for identical questions asked multiple times. This can be considered unacceptable in an industrial setting.
- The 4k token limit: the API’s 4k token limit proved to be quite restrictive for the results of certain queries. The screenshot below is a response file that’s almost hitting the limit. The file contains about 10k characters.

- The importance of description: more detailed description improves the accuracy of the model when selecting which function to call. For instance, for the function that provides asset details, I initially described it as “Get details of an asset record by AssetNum”, OpenAI correctly call this function when asked: “What is the status of asset 11450?”. However, it couldn’t answer the question: “Are there any active work orders on this asset?”. Until I updated the description of the function to “Get details of an asset record by AssetNum. The result will show a list of all open/active work orders on this asset and a list of spare parts”, after which it was able to answer correctly.
In conclusion, despite several limitations, I believe integrating LLM with an enterprise application offers immense potential in addressing various use cases. I am eager to hear your thoughts on potential applications or suggestions for new experiments. Please feel free to share your thoughts in the comments. Your input is greatly appreciated.



