I spend a large portion of my time working with mobile solutions, but I haven’t talked much on this topic. In this post, I will give a bit of praise to EzMaxMobile.
Why should you listen to me: I know a bit about mobile solutions for Maximo. I’ve done several (failed) pilots with the Maximo mobile suite (of the olden days). I’ve built a mobile app which is pretty successful and is being used by some large Oil & Gas operators. I have a bit of experience on a few small Anywhere projects, with Datasplice, and a few smaller home-grown apps.
Why shouldn’t you listen to me: the settings and the level of my involvement for each of the above projects/deployments are vastly different, as such, my opinion on this matter is heavily biased (toward EzMaxMobile).

Back to the topic, as of today (2020), I think EzMaxMobile is by far the best mobile solution for Maximo. There are many things that InterPro (and Chon Neth, the original author of the popular Maximo Times blog) have done right with this product. Below are the 3 things I love the most:
- Consistency with Maximo: EzMax uses the same business layer with Maximo and inherits all MBO business logic. It means, 90% of all logic customization done in Maximo automatically flows through to the mobile app. It includes integration processing rules, MBO java extension, automation scripts, security settings, and error messages. If you’ve heard of the phrase “the best code is no code at all”, you will appreciate to know that they’ve achieved exactly that with this product. On this point, EzMax is the clear winner when compared with Datasplice because EzMax is built for Maximo, while Datasplice is built as an independent work management mobile app that works with both SAP and Maximo.
- A great open framework: in certain cases, there are still rules that need to be configured on the Mobile app only. For that, EzMax has a great framework that is very similar to Maximo architecture which consists of a core library (which we can decompile to understand the logic), and MVC components of which the source code is provided. Third-party implementers like me are free to modify and extend any logic to meet user requirements. The business layer is written in Java, as such, we don’t need to know native mobile development skills such as Android or iOS to customize the app. It definitely doesn’t need Android Studio and/or Xcode (which needs a MacBook), that’s another big plus. Having experience building mobile app before, I can tell it’s easy to build and deliver an app with a predefined specification. Most developers of home-grown apps will be stuck at that, building and implementing their own app. Ability to build an open framework and enable 3rd party implementers to build and extend on top of that is a totally different level. So just for this point alone, my hat’s off to you, Mr. Chon.
- Instant development loop and ease of deployment: this is probably what I love the most when working with EzMax. Instant development loop means immediately after updating the code, I can see the result. On production, full redeployment takes 5-10 minutes. However, most small changes can be done on-the-fly without downtime, and users see the change immediately. On other platforms where compiling the code to native iOS/Android app is required, we usually have to wait for 10-30 minutes to compile the code in XCode/Android before you can run it. Then redeployment, then users have to re-install the app. Although it doesn’t sound that interesting to the business users, it will directly translate into the much higher overall productivity, and thus, lower cost for the customer. In a recent project I involved, it took me less than 10 hours of dev work to cover minor screen changes which include 100+ fields in about 20 app screens. For Anywhere, it’s likely to take me one full man-month or more, not to mention, many of the changes wouldn’t be possible in Anywhere in the first place. (And a small note: when a developer loves something, it directly leads to a much higher quality product and happy users; when a developer hates something, it means glitches, frustration, and meeting room arguments)
To be fair, there are certain things I don’t like about EzMaxMobile. For example, Offline mode has a different code structure, i.e. any screen changes need to be done twice for the online and offline screens. Besides, Offline functionality is also more limited than Online. This is the inherent problem with any offline mobile app. Think about it: an offline app will need all 3 layers: database, business, and UI in one mobile device. In other words, full capability means you need the whole Maximo system running on a mobile device, which is impossible. However, on this aspect, Anywhere does provide smoother transition between Online and Offline. Anyway, it doesn’t really matter much when Anywhere’s capability is too limited in the first place.
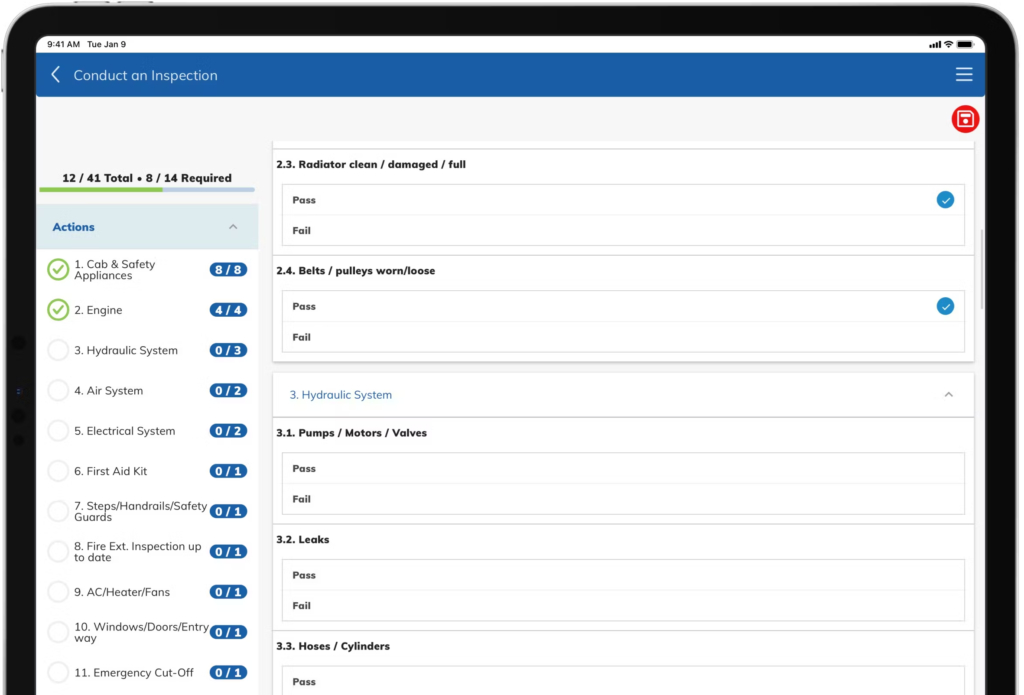
Again, this is my personal and very biased view. I currently work for a company which provides EzMaxMobile implementation service (means I spent a lot more time working with EzMax). However, I don’t have any involvement in business development, thus I don’t have any obligation or receive any benefit for promoting it. In fact, we do provide implementation services for both EzMaxMobile and Anywhere. However, I think compared with Anywhere, EzMax is far more practical. In my opinion, IBM would do the Maximo world a favour by ditching Anywhere and acquire Interpro.
As for the Maximo users, I cannot say in general which mobile solution is the best for you as there are many other options out there (e.g. EAM360, Informer). It also largely depends on what local providers are available in certain countries and the products they use. Most of the time, the success of an implementation depends on the consultant, not the product. Thus, my suggestion is, if you are thinking about implementing a mobile solution, don’t just blindly go for a “default”, brand-name solution. Do your homework by getting quotes and demo on a list of specific requirements. For mobile solutions, the requirements are usually simple, focusing on a few tasks that add value to a worker if done on the field. It is not difficult to define specific requirements during the RFx processes. If you don’t know what the requirements are yet, do a small pilot with an out-of-the-box installation first. License, server, and installation service are cheap. It’s the customization that costs the most. How about starting with a trial license or 5 named-user licenses, no customization, then get some feedback from the field guys? It’s not a bad idea to do a dual pilot, then comparing products side-by-side. I’ve seen one or two clients who did just that, and it saved them a lot of money and frustration over the long run.