Most Maximo settings or Java code can be deployed by copy/paste the file directly to the installed folder in Websphere without having to rebuild and redeploy the application. However, with web.xml, it doesn’t work that way. Sometimes, we need to update this file to increase the timeout setting or enable/disable LDAP integration
Sure, we can directly modify the file in Websphere without redeployment, but we will also have to update the file in a few temporary folders for which, I find the process quite tedious.
To avoid having to rebuild and redeploy the whole maximo.ear file, which can take a lot of time, we can just redeploy the single web.xml file instead. Below is the process:
Update the web.xml file with new settings
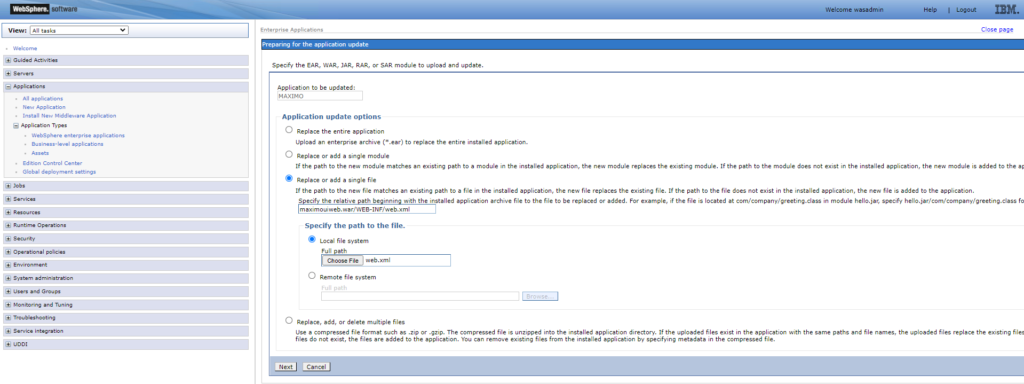
Log in to the Websphere console, open Applications > Application Types > WebSphere Enterprise Applications: select “MAXIMO” application by ticking on the checkbox next to it, click on the Update button
In “Application update options“, select “Replace or add a single file” option
In the textbox below “Specify the relative path….“, specify: maximouiweb.war/WEB-INF/web.xml
In the “Specify the path to the file“, choose “Local file system“, and click on “Choose file” to browse and select the updated web.xml file, click Next.
Click OK on the next screen to deploy. Click Save when the deployment process is completed.
Wait for a minute for the new settings to be propagated to all nodes, then restart Maximo.
I want to post a simple JSON message to an external system and do not want to add any external library to Maximo as it would require a restart.
In the past, I used the Java HTTPClient library that comes with Maximo, but it would require half a page of boilerplate Jython code. Recently, I found a simpler solution below.
Step 1
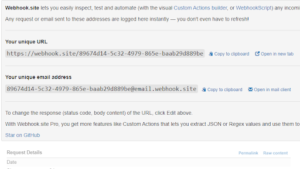
First I use WebHook as a mock service for testing. Go to webhook.site, it will give us a unique URL to send request to:
Step 2
Go to the End Point application in Maximo to create a HTTP Endpoint
End Point Name: ZZWEBHOOK
Handler: HTTP
Headers: Content-Type: application/json
URL: <copy/paste the Unique URL from webhook>
HttpMethod: POST
Step 3
To ensure it’s working, Use the Test button, write some simple text, then click on “TEST”. Maximo should show a successful result. In Webhook, it should also show a new request received. (Note: if it gives an error related to SSL, it’s because Websphere doesn’t trust the target website. You’ll need to add the certificate of the target website to Websphere trust store)
Step 4
To send a request, just need two lines of code as follows:
Just to document a weird issue I had today. I was attempting to configure LDAP (Microsoft AD) for Maximo/Websphere. After it is configured (and I’ve tested that it can query AD data), Application Server security was enabled. Then the server is rebooted to refresh the new configuration.
After a restart, ctgNode01 (node agent) service cannot start. Node Agent log shows the error below:
WSVR0100W: An error occurred initializing, nodeagent [class com.ibm.ws.runtime.component.ServerImpl]
com.ibm.ws.exception.ConfigurationError: com.ibm.websphere.ssl.SSLException: CWPKI0316E: Cannot get a security object from the configuration. This can indicate that the security.xml file for the cell is corrupt and you must validate the integrity of the file.
I looked it up on the web, there are some suggestions about a corrupted security.xml file. So I checked and found that the security.xml file in ctgAppSrv01 profile is completely empty. I looked at other Maximo servers and found this file has an exact same content with the security.xml file from ctgDmgr01 profile. I copied that file over to AppSrv profile, restarted Websphere and it is able to start again.
Not sure why configuring LDAP would completely wipe out the content of this file.
I needed to send an external system a file import request. The external system would take some time to process the file before the import result can be queried. Making a status query immediately after the import request would always return an “import process is still running”. It’s best to wait for a few seconds before making the first attempt to query the import status.
It took quite a bit of time to look up the web for a “wait” or “sleep” function. Some posts suggested using Java flow, some recommended complex processes or involved an external library.
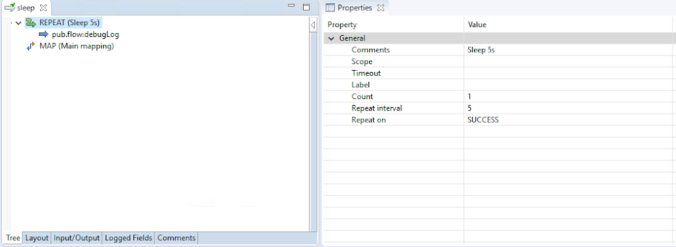
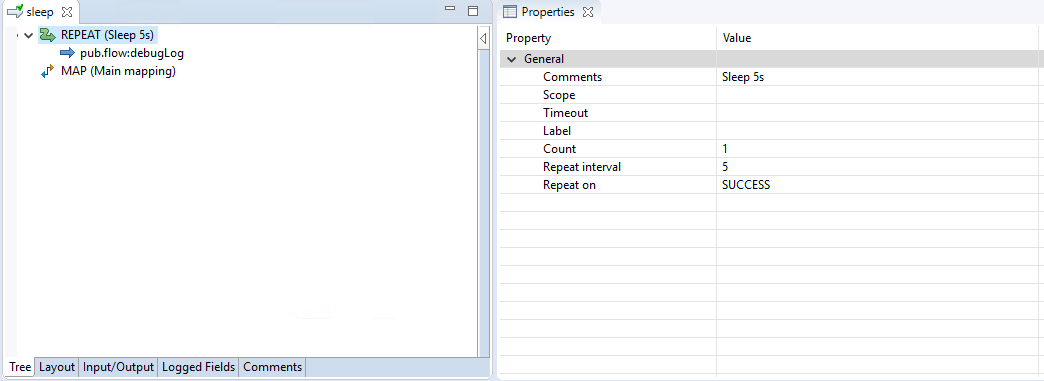
The easiest method I finally settled with is to use Repeat as follows:
Essentially, the flow would repeat 1 time in 5 seconds before getting to the next step (Main Mapping). The repeat loop does nothing other than just writing a line in the server log to make troubleshooting a bit easier.
One of our clients undertook a massive IT transformation program which involved switching to a new financial management system, upgrading and rebuilding a plethora of interfaces among several systems, both internal and external to the business. Kronos (now UKG) was chosen to replace an old timesheet software and there was the need to integrate it with other systems such as Maximo and TechnologyOne.
WebMethods was used as the integration tool for this IT ecosystem. This is my first experience working with Kronos. The project took almost two years to finish. As always, when dealing with something new, I had quite a bit of fun and pain during this project. As it is approaching the final stage now, I think I should write down what I have learned. Hopefully, it will be useful for people out there who are doing a similar task.
The REST API
Kronos provides a fairly good reference source for its REST API. Theoretically, it offers the advantage of supporting real-time integration and enables seamless workflow. However, we don’t have such a requirement in this project. On the other hand, this has two major limitations.
API throttling limit: it restricts the number of calls you can make based on the license purchased.
Designed for Internal Use: it is obvious to me that the API was built for internal use of the application. It is not built for external integration.
No one told us about this when we first started. As a result, we hit several major obstacles along the way:
First, most API calls will need to be method specific. For example, Cost Center requests need to be either Create New, Update, or Move. There is no Sync or Merge operation. The Update and Move requests will accept Kronos’ Internal ID only. When sending an Update or Move request, we need to send another request first to retrieve the Internal ID of a record.
Cost Center has a simple structure with a few data fields. However, to get it to work, we had to build some complex logic to query Kronos to check whether the record exists (and the parent) to send in the appropriate Create New, Update or Move request.
This is not a major problem until the API Limit is added to the equation. If Kronos receives more than certain number of requests over a given period, it will stop processing other requests. In other words, the whole integration system is out-of-service. We had to build a caching mechanism to pre-load and refresh the data at a suitable time so that the number of requests sent to Kronos is kept at minimal. This adds a lot of complexity to an otherwise simple interface.
Kronos API Throttling Limit
With a more complex data structure, such as the Employee master data, if we use the REST API, it is impossible to build an interface that is robust enough for a large scale, high-volume system. We had to build complex business logic in WebMethods to handle all sort scenarios and exceptions that could occur. The process to create a new employee record can result in more than a dozen different requests to check existing data and lookup for Internal ID of different profiles such as Security, Schedule, Timesheet, Holiday, and Pay Calculation Profiles, then send in the Create New/Update requests in the correct order, ensure proper handling of exception and roll back if one request fails due to various reasons.
The Report API
Kronos provides a REST API to execute reports. Besides from the out-of-the-box capability, it is possible to build custom API for reporting too. This is useful to alleviate some of the problems with the API throttling limit.
For example, we have an interface to send organisation hierarchy (departments and job positions) to Kronos as Cost Centers. The source system, TechnologyOne in this case, would periodically export its whole data set to a CSV file. We only need to query Kronos to determine if the record exists to either send a Create or an Update request. If the record has a new change, we need to send an Update and/or a Move requests. In this case, we used the Report API to retrieve the full set of Cost Center in one single call rather than having to make thousands of individual cost centre detail requests.
The Import API
The Import API turned out to the best way to send data to Kronos. We learnt it the hard way. It has some minor limitations such as:
Some APIs use description to identify a record instead of an ID
Documentation sometimes is not accurate.
However, the Import API provides some powerful capability for sending external data to Kronos:
Support bulk upload operation
Auto matching with existing records – does not require querying for Internal ID
Support “merge” operation – automatically decide whether to create new or update depending on whether a record already exists or not
Since this is an asynchronous operation, and the time it takes to process inbound data depends on the volume. We need to build a custom response handler to continuosly checking with Kronos after a deliver to retrieve the status of an import job to handle Success or Failure result. This custom response handling takes some extra effort to build, but it is reuseable for all import endpoints.
As an example, with the Employee interface above, at some point, it became too complex and a maintenance nightmare for us. We had to rebuild it from scratch using the Import API and we were glad that we did. It greatly simplified the interface, and the business is now very confident of its robustness.
List of Import APIs which can be seen after logged in to Kronos
Conclusion
If I need to build a new integration interface with Kronos now, for retrieving data from Kronos and sending it to another system, I will start with using Reports (via the Report API) to identify new updates, then use the REST API to retrieve details of individual records if it is required. For sending data to Kronos, I would look at the Import API first. I will only go for the REST API if the Import API cannot do what I want and only if the request is simple and low volume.
I am a freelance Maximo consultant based in Melbourne. If you enjoy reading my blog, please connect with me on LinkedIn to get updates on new posts. If you or your company need any professional assistance, please leave me a message, I'll call you back.