Working in IT, we deal with strange issues all the time. However, every once in a while, something would come up that leaves us scratching our heads for days. One such issue happened to us a few years back. It came back to me recently and this time, I thought to myself I should note it down.
Summary
- Maximo – TechnologyOne integration error. Work orders went missing.
- There are no traces of problem. Everything appears to be working fine
- The problem is due to the F5 Load Balancer returns a Maintenance Page with a HTTP Code 200. This leads Maximo to think the outbound message was received successfully by WebMethods.
The mysterious missing work orders
The issue was first reported to us when the user raised a ticket about missing work orders in TechnologyOne, the Finance Management System used by our client. Without work orders created in TechOne, the users won’t be able to report actual labour time or other costs. Thus, this is considered a high-priority issue.
Integration Background
TechOne is integrated with Maximo using WebMethods, an enterprise integration platform. Unlike direct integration, these types of problems are usually easy to deal with when an enterprise integration tool is used. We simply look at the transaction log, identify the failed transactions and what caused them, fix the issue, and then resubmit the message. All good integration tools have such fundamental capabilities.
In this case, we looked at WebMethods’ transaction history and couldn’t find any traces of the missing work orders. We also spent quite some time digging through all of the log files of each server on the cluster to find any errors but couldn’t find anything relevant. Of course, that is the case because if there is an error, it should have been picked up and the system should raise alarms and email notifications to a few overlapped monitoring channels we set up for this client.
Clueless
On the other hand, when we looked at Maximo’s Message Tracking and log files, everything looked normal with work orders published to WebMethods correctly without interruption. In other words, Maximo said it had sent the message, while WebMethods said it never received anything. This left us in limbo for a few days. And of course, when we had no clue, we did what we application people do best, we blamed the network guys.
The network team couldn’t find anything strange in their logs either. So, we let the issue slip for a few days without any real progress. During this, users kept reporting new missing work orders not knowing that I didn’t really do any troubleshooting work. I was staring at the screen mindlessly all day long.
Light at the end of the tunnel
Then of course, when you stare at something long enough, the problem will reveal itself. With enough work orders reported, it became clear that all of the updates only went missing during a period between 9 to 11 PM regardless of the type of work orders or data entered. When this pattern was mentioned, it didn’t take long for someone to point out that this is usually the time when IT do their Windows patching.
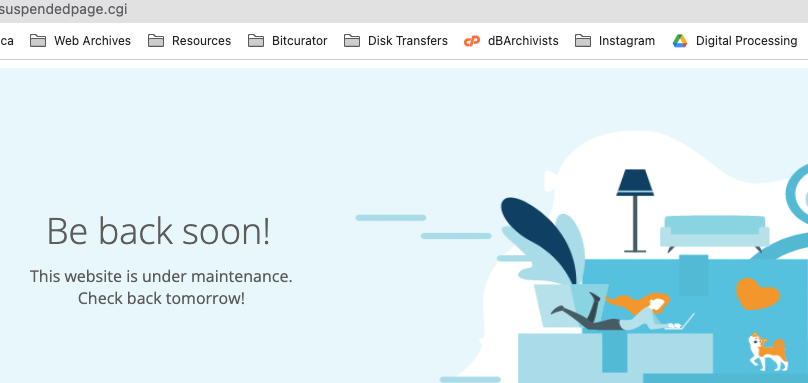
When a server is being updated, IT would set the F5 Load Balancer to re-direct any user requests to a “Site Under Maintenance” page, which makes sense for a normal user accessing a service via the browser. The problem is that when Maximo published an integration message to WebMethods, it received the same web page, which is ok, as it doesn’t process any response. However, the status of the response is HTTP 200 which is not ok in this case. Since it’s an HTTP 200 OK status, Maximo thought the message had been accepted by WebMethods and thus marked it as a successful delivery. WebMethods, on the other hand, never received such a message.
Lesson Learned
The recommendation in this case is to set the status of the Maintenance page to something other than HTTP 2xx. When Maximo receives a status other than 2xx, it marks the message as a delivery failure. This means the administrator shall be notified if monitoring is set up. The failed message will be listed as an error and can be resubmitted using the Message Reprocessing app.
Due to the complex communication chain involved, I never heard back from the F5 team on what exactly was done to rectify the issue. However, from a quick search, it looks like it can be achieved easily by updating the rule in F5.
This same issue recently came back to me, so I had to note it down to my list of common issues with Load Balancer. I think it is also fun enough to deserve a separate post. This is a lengthy story, if you made it this far, I hope at least it will be useful to you at some point.