Being Maximo consultants, we often come into a scene where the client gives us MAXADMIN access to the system but access to the database is an absolute No-No. This is usually the case with companies that have a clear separation of the App Admin and DB Admin roles. This is also one of the key restrictions with Maximo as a Service.
If you have been doing a bit of admin and config activities, you will surely understand the limitation of having no database access. It’s like having to work with tied hands. Luckily, we can use MXLoader to query/update almost any data tables in Maximo. Below is an example on how to do it.
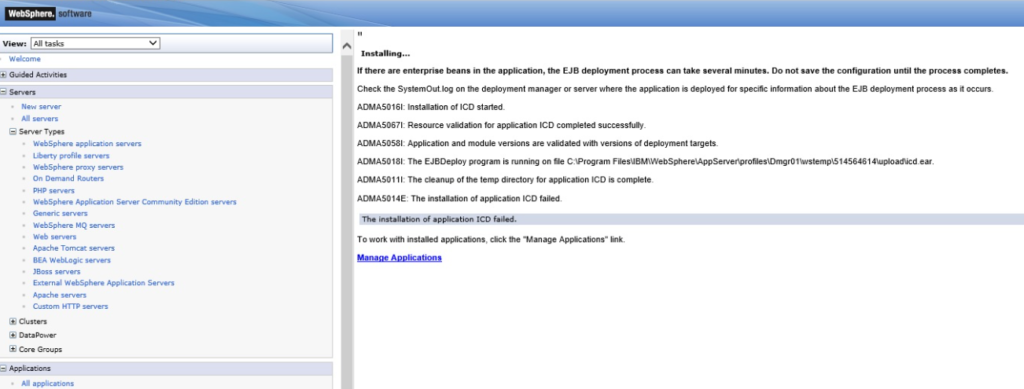
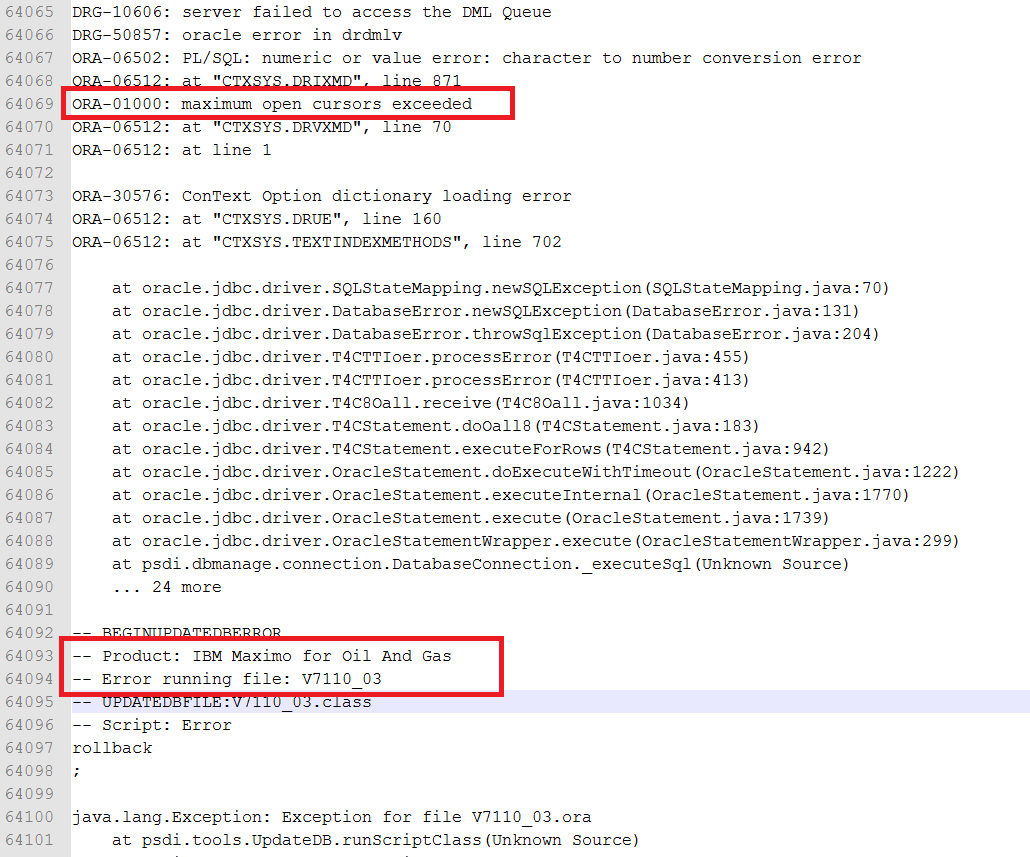
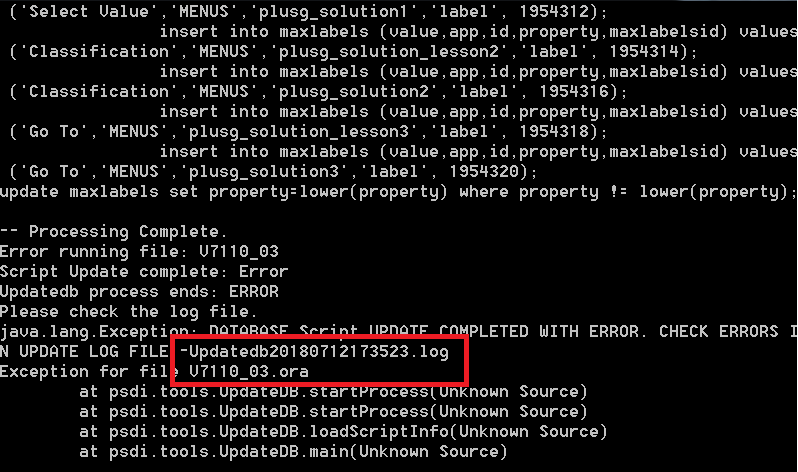
Let’s say we’re working with a Maximo SaaS and IBM only gives us front-end admin access, but no access to the back-end. Sometimes, Maximo is stuck while applying DB config, and we cannot turn off Admin Mode. This is usually not a big problem when we have full DB access. To fix this, we simply have to update the CONFIGURING flag in MAXVARS table to 0. However, with Maximo on the cloud, under standard procedure, we’ll need to raise a support ticket asking for IBM to update the flag. This could take a few days to resolve. It’s a horrible situation since we cannot do anything while Maximo is in Admin Mode.
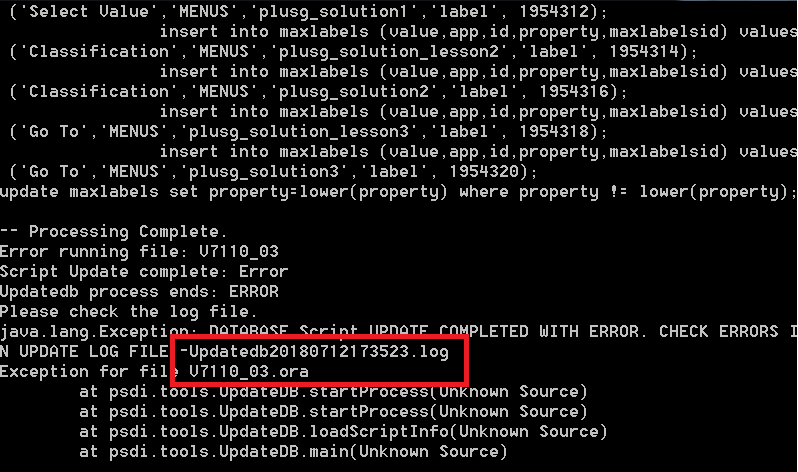
Without DB access, we can update the MAXVARS table using MXLoader using the steps below:
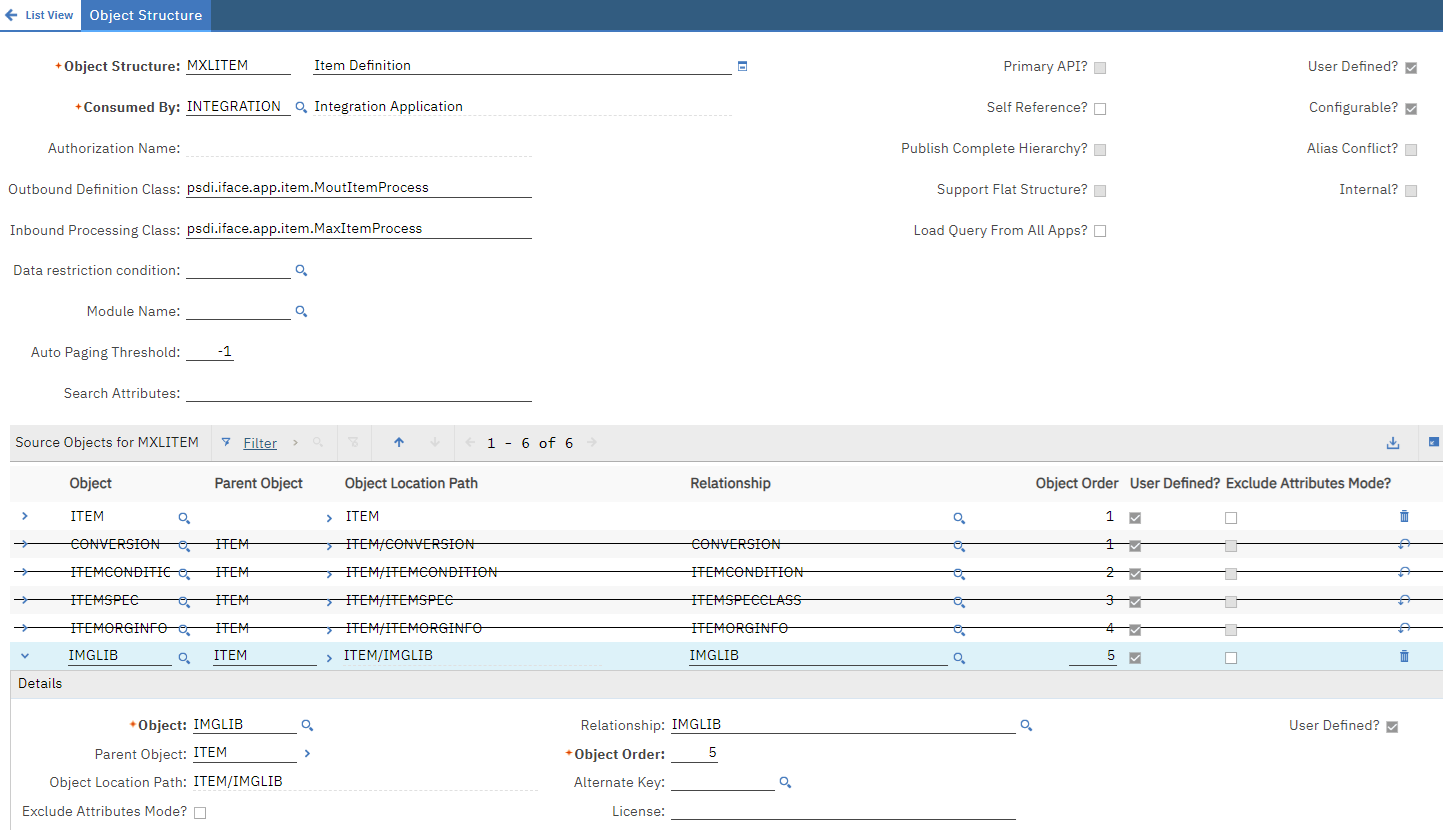
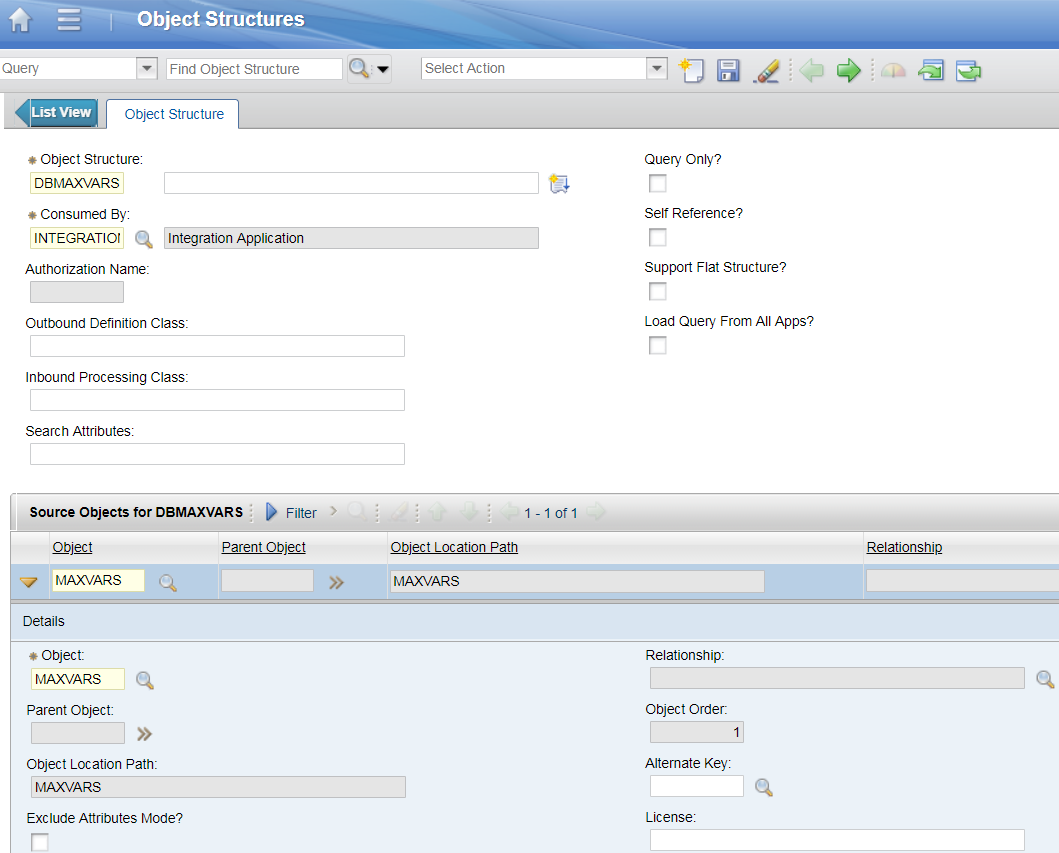
1 – Create an Object Structure for the MAXVARS table:
- OS Name: DBMAXVARS
- Consume By: Integration
- Add a new row, set Object Name: MAXVARS
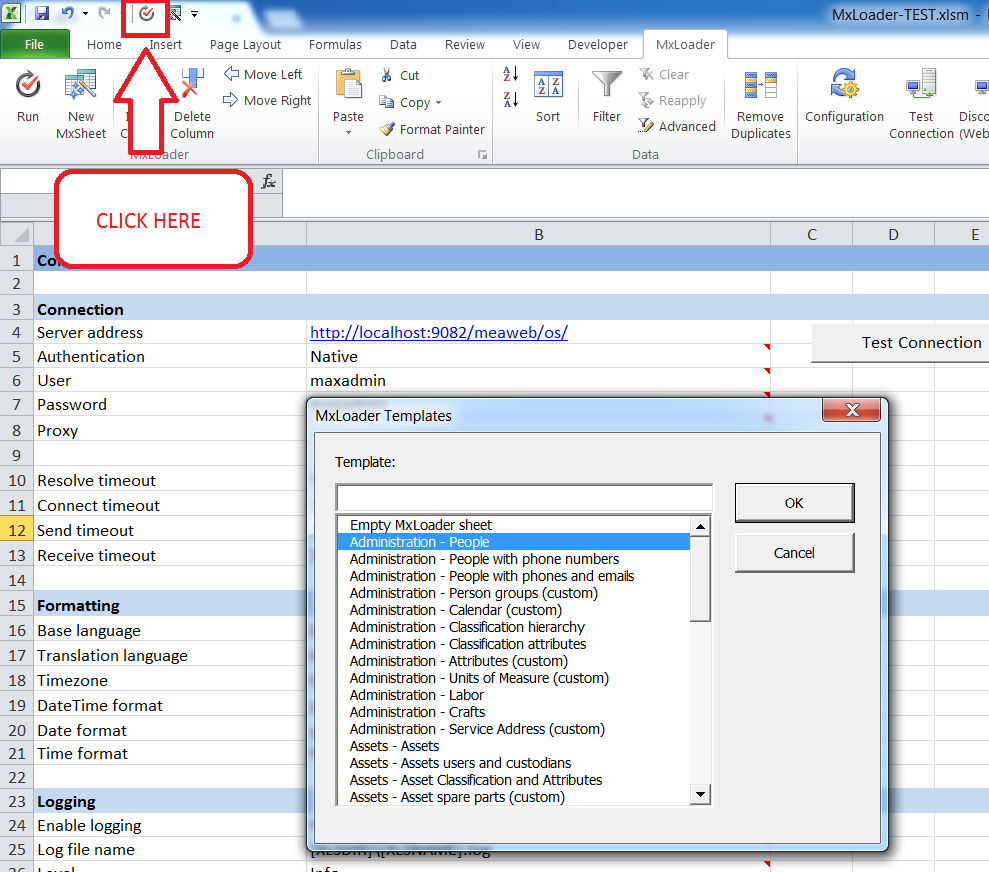
2 – Use MXLoader, add
a new ‘PEOPLE’ sheet:
a new ‘PEOPLE’ sheet:
With the new ‘People’ sheet added, replace ‘MXPERSON’ object structure with ‘DBMAXVARS’ and ‘PERSON’ object with ‘MAXVARS’ object. To identify what columns are available MAXVARS table we can open the ‘DBMAXVARS’ object
structure, and open the ‘Exclude/Include fields’ dialog from the Select Action
menu. In this case, I only need two fields: VARNAME and VARVALUE
structure, and open the ‘Exclude/Include fields’ dialog from the Select Action
menu. In this case, I only need two fields: VARNAME and VARVALUE
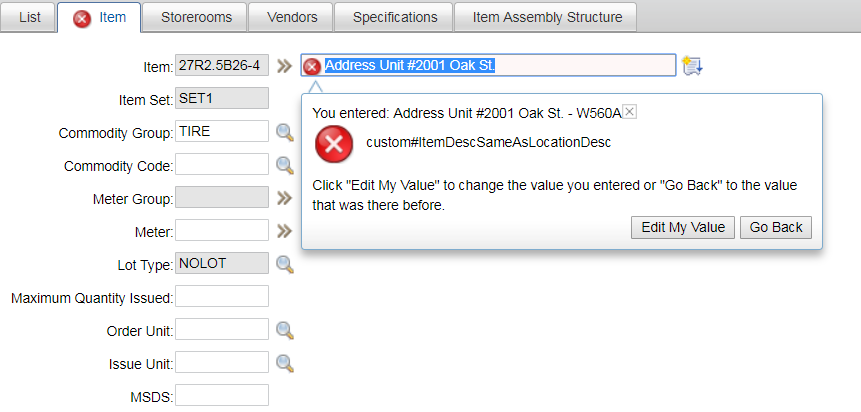
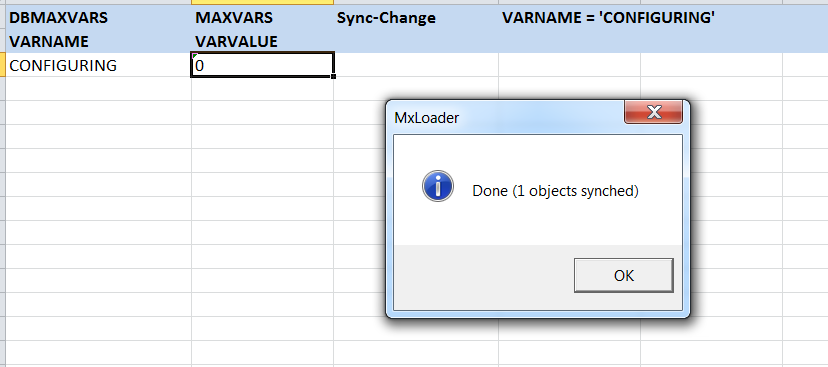
3 – Set operation method to ‘Query’ and where clause to VARNAME
= ‘CONFIGURING’, then execute the query by clicking on the ‘Run’ button to retrieve
the record.
= ‘CONFIGURING’, then execute the query by clicking on the ‘Run’ button to retrieve
the record.

4 – After we get the record for ‘CONFIGURING’ variable, set VARVALUE to 0, then change the operation method to ‘Sync-Change’ then execute the operation. We will now be able to turn off Admin Mode.
Some other examples of using MXLoader to update the system
tables include:
tables include:
- MAXMENU – To move/add an app to a different module menu
- APPFIELDDEFAULTS – To set a default value when inserting new
record - MAXSESSION – To release user sessions that got stuck in Admin
mode and the user cannot log in - MAXDOMAIN – To create a new Synonym Domain
In case we do not have permission to use the Object Structure application, another method is to create a new single-page application using Application Designer to expose data of the object on GUI. It would enable us to achieve the same result and only take a few minutes to do. However, I like MXLoader a lot more as we can use it to bulk insert/update normal app data, and it doesn’t leave a bunch of junk apps in the system which is quite difficult to remove.
The policy to restrict DB access is usually there for a good reason. And MXLoader is an extremely powerful tool. I find it a lot easier to make mistakes updating the wrong data or to the wrong environment. So please be very careful when using it and you should always have a backup of the before and after versions of the data set that you work on.
[Update 2023]: an easier and more powerful way to achieve this task is using API Automation script