Introduction
If you have been working with Maximo for a while, you already know about the Download button on the top left of every table in Maximo. With one click, it will export everything we see displayed in the table into an Excel file. This is great for doing further data analysis and reporting from that data. It is so simple and convenient, right? Not quite.
Performance Degradation
The danger with the Download button is that, since it is too convenient, everyone is using it for every data requirement. One frequent problem is the user keep asking us to add more columns to the List tab of the key applications like Work Order Tracking. Most of the time, the Maximo Administrator will comply to such requests in a blink (another problem of Maximo being too easy to customize). Often, many of those columns are retrieved via relationships. One additional column usually does not really make much difference. But if there is a high number of records, and as the amount of user activities increases, it will create a snowball effect in degrading the overall system performance and people will start complaining about Maximo being slow.
However, the real problem with the Download button is that, by default, there is no limitation set for it. Usually after Maximo was first implemented, it worked great. After several years, the amount of data grew, and people start using this method to download data for various reporting requirements. The Download button can significantly affect system performance.
Measure the impact
For a client that I recently worked with, many users frequently use the Download button to extract a large amount of data (e.g. all work orders in one year) to create their own reports in Excel. This led to a tremendous amount of stress on the servers.
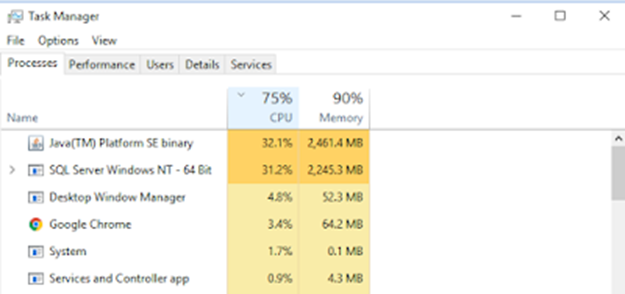
First, we must realize that the output of this “Download” function is an XML file (although the extension is XLS), Maximo consumes a lot of processing power and memory to generate the XML file. To fully understand how it affects the server, I did a small test by setup a copy of the client’s database a local VM. I opened the Work Order Tracking app and try to download all active work orders (15k records). That took around 15 minutes to generate and download the file. Then I tried to download all work orders reported in the last year (this includes both closed and active work orders). It took 50 minutes. And during this whole time, the VM’s CPU and memory utilization was saturated the whole time.
Crashing the server
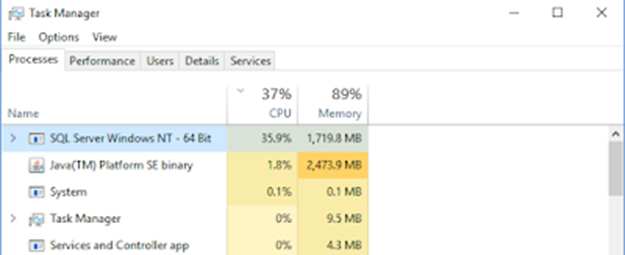
To test the worst-case scenario, I opened the SR application, and click on “All Records”, then clicked on the Download button to download all 600 thoudsand records. Users can easily make this “mistake”, and once they clicked on the Download button there is no option for them to cancel the process.
At first, the process saturated CPU and memory utilization for more than an hour, after that, the session expired. However, in the background, SQL Server process continued running. It was consuming 30-40% CPU utilization for the entire day. I left it to run for about 6-7 hours until I got fed up and had to restart SQL Server to kill that process. Theoretically, since I was the only user in the system, when the process was running and it reached the maximum JVM heap size, Garbage Collector would try to clean the other previous MBOs which it has used, and able to free up some memory.
However, in the production environment, as it happened to our client, if the server load is high, sometimes, the Garbage Collector couldn’t free up memory quick enough, it resulted in the OutOfMemory error and crashed the server.
What can we do about this problem?
To reduce the impact of the Download function, we should set a limit on the number of records the user can download by setting a value to the webclient.maxdownloadrows property. There are already some tech notes by IBM that talked about it.
However, the next question is, once we have set a limit, what is the alternative method for the user to download the data they need? I can think of a few methods like building a simple BIRT report. It allows the users to choose XLS as the output format. We can also setup Application Export function with a flatfile output format. But my favourite option would be using the “Create Report” function. By default, when we create and run a report in the “Preview” mode, it exports the exact same number of columns on the List tab of an application, then we can “Export Data” from that report. The process takes a few clicks, but processing time is usually less than one minute compared to 10 or 20 minutes. That’s a quick win. Also, once the user got used to it, they can extract any data that they like. That means less work for the Maximo Administrator.