Recently, I started playing with Azure by attempting to migrate a Maximo instance from my local VM to Azure platform. Although the attempt was a success. I didn’t realize SQL Server and Azure SQL are different databases (or more correctly, two different versions). There were a few issues during the process, but I figured out how to work around them and got Maximo running on Azure VM and Azure SQL. After sharing the result on LinkedIn, there were some comments that Maximo couldn’t be installed on Azure SQL and IBM doesn’t support it, so I spent a bit more time digging and thought I should share the details and some of my opinions on this matter.
First, let us be clear, Azure is a big cloud platform which offers many different services. I’m not a cloud expert, but from what I understand, we are talking about two main services:
- Azure VM: which is IaaS and it lets us run a virtual machine on the cloud. You can run many different Windows or Linux versions on it; it is transparent to the standard business applications (Maximo). In other words, there shouldn’t be any issue running Maximo on Azure VM as long as you stick to the OS versions supported by Maximo. For example, when referring to Maximo 7.6.1.1 Compatibility matrix, Microsoft Hyper-V 2012 and 2012 R2 are supported, and with them, Windows Server 2012 and 2016 are supported as Guest OS. In fact, many companies large and small are running Maximo on Azure VM.
- Azure SQL: is a cloud version of SQL Server. It has the core engine of SQL Server database, but certain aspects of it has been modified to work on a cloud environment and to support multi-tenancy. Current version of Maximo doesn’t support Azure SQL, and IBM don’t have any plan to support it in the near future with Maximo 7.6.1.x and 8 (according to their 2020 Roadmap).
Even with that knowledge, I was still curious on whether I can make it work from technical perspective and did a few experiments:
A – Installing Maximo 7.6.1 from scratch on Azure VM and Azure SQL:
People mentioned that Maximo cannot be installed on Azure SQL, so I did just that, just to know what exactly the issue is (and secretly, I hoped I could fix
it). I followed the standard Installation process and managed to install
Websphere, prepare the environment, and install Maximo SMP.
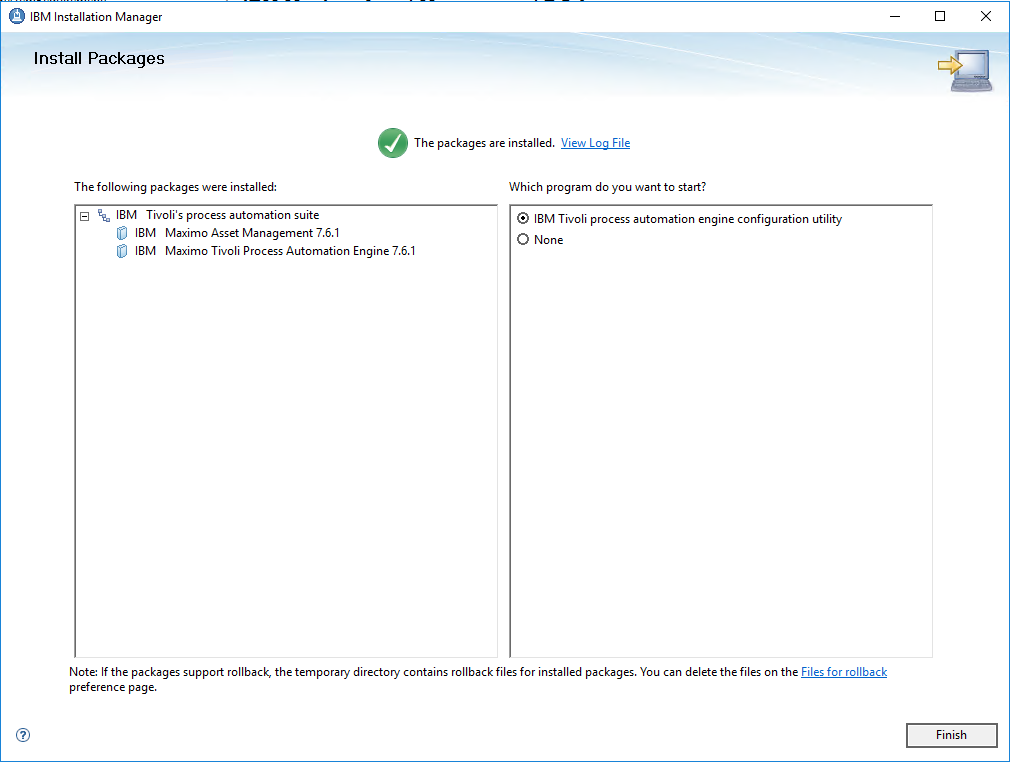
After SMP was installed, I couldn’t get the Configuration tool to connect to Azure DB because it couldn’t resolve the DB Alias provided by Azure.

I attempted to execute this step manually using command line by setting up the
maximo.properties file, then run the maxinst.bat tool. However, DBC script failed when it ran an undocumented DBCC ‘CALLFULLTEXT’ command:

To be honest, installing a fresh Maximo DB on Azure SQL shouldn’t be a problem from technical perspective, because we can always install it on an on-premise SQL
Server, then put it on to Azure SQL (using the process I described in my previous post). However, this is definitely a failure.
B – Upgrading Maximo from 7.6.0.6 to 7.6.0.9
It is critical to be able to upgrade and install updates, fix packs, or industry add-ons. From technical stand point, all of these activities are essentially the same process; it involves running a large number of DBC scripts, which mostly consists of SQL commands. I wanted to see if it works on Azure SQL.
I started out with a simple task first: upgrading from Maximo 7.6.0.6 to 7.6.1. To do this, I simply replaced the existing 7.6.0.6 SMP folder installed previously with a new 7.6.1 SMP folder, then run the updatedb tool. On the first run, I had several issues related to incompatible collation between “Latin1_General_CI_AS” (default setting of on-premise SQL Server) and “SQL_Latin1_General_CP1_CI_AS” (the default value of Azure SQL’s databases, which can be changed, and the ONLY supported collation of master and tempdb).
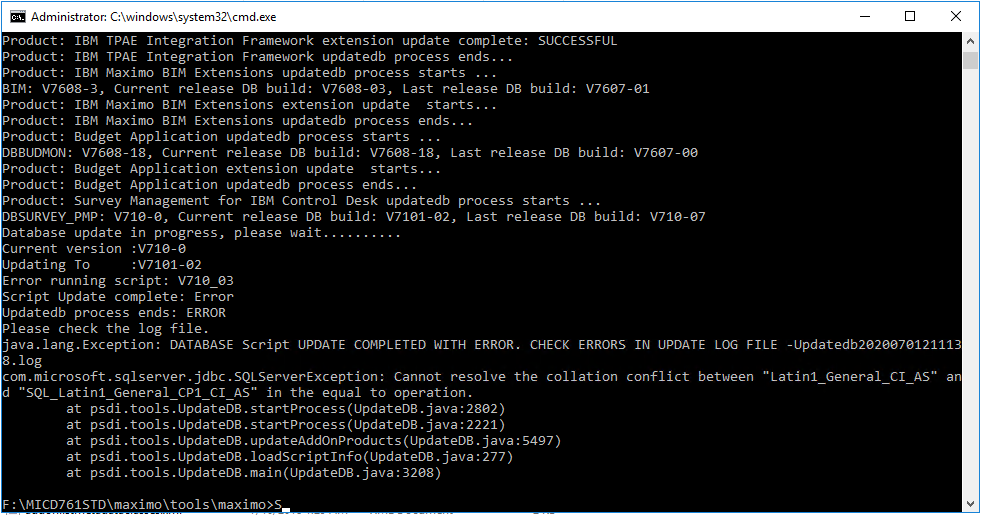
Changing a database collation is a complex job which involves updating the value at all three levels: database, table, and column. To do it, we have to drop all indexes and constraints on the tables, then run the update script, then re-create the indexes. I only wanted to find out if upgrade is possible, so I tried again with a fresh Demo DB created with “SQL_Latin1_General_CPI1_CI_AS” collation. The upgrade is successful this time. So, that is a small success.
C – Install Add-ons
Next, I tried installing some serious industry add-ons (Scheduler 7.6.7, Oil and Gas 7.6.1, Utilities 7.6.0.4, Control Desk 7.6.1) on top of the working instance from the previous step. These are probably the most complex add-ons we could get for Maximo. As such, if it worked, there wouldn’t be any problem to get it to work with any future upgrade/update.
The process failed when it tried to run some scripts belong to the ICD add-ons. This time, it had an issue when trying to access object spt_values in the master DB which will never be given in a multi-tenancy cloud environment. There were a few posts on the web showing us how to work around this issue. But I stopped that this, and that is the end of my attempt. There’s no point in trying to spend too much time in getting something to work knowing it is not supported by IBM (unless there are some clients willing to pay for my time doing that in the future)
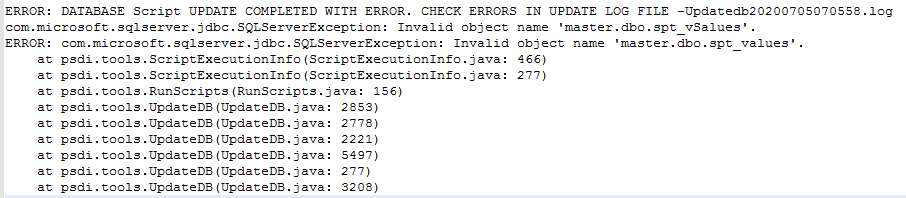
Conclusion: the result of this process confirms what others have reported, Maximo doesn’t work with Azure SQL database. Although the issue with collation can be worked around (with a lot of effort), there are more than one issue with various DBC scripts requiring access to the master DB which is not possible in Azure DB. For people with extensive knowledge on DBC scripting and custom DBC handler, they might be able to modify the problem scripts to get it to work, but that is definitely not supported by IBM and the effort cannot be justified in my opinion. As support for Azure DB is not on the road map. At this stage, our only option is to use on-premise DB version installed on the cloud as a separate DB server.