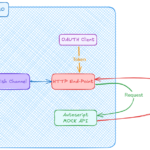
Sometimes in our application, we need to build custom services that run when Maximo starts. We can extend the psdi.server.AppService class and register it with MXServer by inserting a new entry into the MAXSERVICE table. If the service executes slow-running queries, it is a good idea to cache the data in memory to improve performance. We can implement MaximoCache interface for this purpose. By doing this, we can initialize the service when MXServer starts and pre-load all data required by the service into JVM memory. When the service is called, it will only use cached data to provide instant response which gives a much better user experience.
Below are the steps to create a sample service that loads all Location’s descriptions into memory. The service will provide a function to check if an input string matches a location’s description or not. We will call this check when the user enters an Item’s description and it will throw an error whenever the input matches with the description of any existing Location. This is not a very good use case. But for the sake of simplicity, I hope it gives you an idea of how it can be implemented.
1. Create a LocationCache class, implementing psdi.mbo.MaximoCache interface:
For the getName() function, set a name for the cache, such as “LOCATION_CACHE”.
Create method loadData() to query and load all locations’ description into a HashSet
Call the loadData() method in the init(), reload(), reload(String) function overridden from the MaximoCache interface
Create function isLocationExist(String) to check if an input String matches with a description contained in the HashSet
2. Create a LocationCheck class extending the psdi.server.AppService class. Override the init() method to initialize a new LocationCache object and add it to the MXServer’s cache.
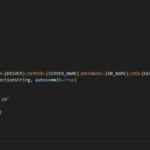
3. Insert a new entry into the MAXSERVICE table to register with MXServer to initialize the service when Maximo starts. Sample SQL statement to insert the record as follows:
4. Extend the LocationSet class to override the fireEventsAfterDBCommit() method. Essentially this method will reload the cache whenever there is a change to location data. This will ensure that the information stored in the cache will always be in sync with the new update.
5. Create a FldDescription class to override the validate() method, and associate it with the Item.Description field. In the validate() method, we will check if the description entered is the same as a location’s description stored inside the cache and throw an error dialog if there is a match.
You can view or download the full sample code from this GitHub repository: link
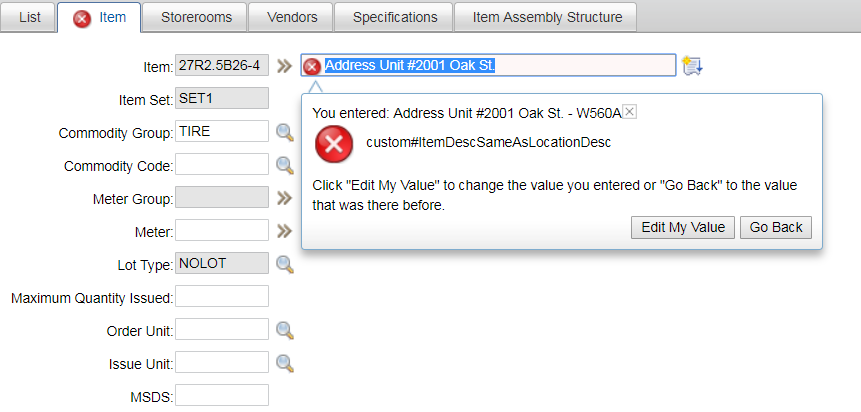
After deploying the code and associating the LocationSet to the Location object and the FldDescription class the Description field of the Item object, to test if the code works, open an Item and enter a description that matches the description of a location, it should throw an error message as in the image below:
To check if the cache is reloaded properly, create a new location or update an existing one, enter the description of the updated location to an item’s description, it should also throw an error message.
Last week, I played around with Oracle’s new toy: the InMemory feature available in Enterprise Edition. Although it made Maximo runs 1.25x faster, but it didn’t meet my expectation which was from 2x to 5x. This has bothered me for the whole week and I kept thinking about it.
If you’ve read my previous blog post, the one thing I pointed out which could lead to no performance improvement is that I ran the test on a tiny demo version. It has only a few hundred assets and less than a thousand work orders. So, any heavy processes or poorly written queries couldn’t make the database 1 second slower. This week, I set out to do a more elaborate test with a setting that looks more similar to a real production environment. At first, I setup my system as follows:
For Maximo: v7.5 with several industry solutions and add-ons. The data includes 4M work order records, 200k Assets & Locations, 200k Issue Transactions, and 1M Labor Transactions. Total size of the DB is more than 50GB.
Oracle 12c Enterprise: 3GB allocated to PGA, 11 GB allocated to SGA (which includes 6GB allocated to InMemory data store)
For App Server: Virtual Box running on Mac OS host: Core i5 2.3 GHz, 16GB RAM, SSD 512GB
VBox configuration: Windows 2012 x64, 12GB RAM
Websphere: Cluster with 3 JVMs x 3GB each.
I got one problem though. The two machines connected wirelessly to each other via a home wifi router which gave a latency of between 5ms to 20ms, sometimes it went up to 100ms or even timeout. This resulted in the system ran with unpredictable performance. In practice, network connection between Application Server and DB Server usually have a latency of < 1 ms. So I abandoned the idea of having the system runs on two separate boxes, and returned to a configuration with everything runs on one laptop as follows:
Database: PGA – 3G, SGA – 8G (5G of which is InMemory)
Only one MXServer JVM with 3 GB
I intended to test and compare following operations:
Run a Saved Query on Work Order Tracking app
Generate 7 PM Work orders at once
Change status of 27 Work orders at once
Run a simple Report created by “Create Report function” which joins two tables: Work Order and Asset
Run a more complex report which joins a few tables including Work Order and Actual Labor and Actual Material
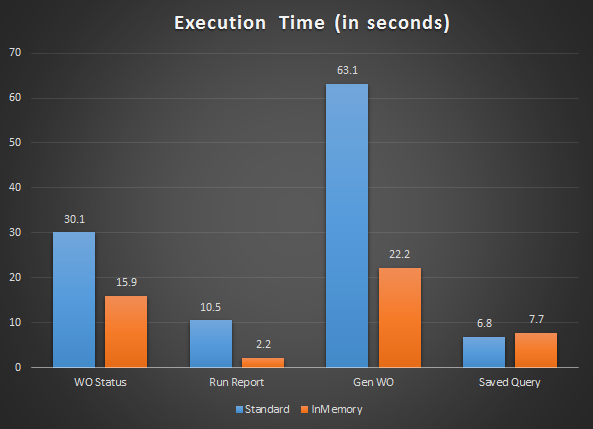
For each of the operations above, I ran test three times to get the average execution time (I ignored the first run as it is usually longer since data hasn’t been populated and cached to memory yet). Below is the result:
For the running saved query, I don’t understand why it took longer to load (result was consistent, not random)
For other expensive operations, Maximo ran 2-3 times faster.
For the more complex report, it never finishes. I tried several times and with the longest one I waited for 50 minutes before killing the process (I checked and Oracle was still processing, not hang). Even after turning on InMemory, it took more than 20 minutes, then I killed it as I was too tired to wait.
For the simple report, it is 5 times faster. If we pay close attention here, the BIRT report window took more than a second to open already, which means DB query returned result almost instantly. This made me believe that we could get a 10-15x performance gain for reports that take several minutes to run.
Since I had to abandon my original setting with two laptops, and also, because I was too lazy to build a new report which will take around 5-20 minutes to run on this environment, I couldn’t test a heavier load scenario with several expensive read/write operations like PM Gen, WO Change Status, and running several slow reports at once. This kind of load is what we normally see in production and usually slow down the system significantly because operations and queries have to wait for each other to release resource lock. But this situation is exactly where InMemory will make a huge difference.
Anyway, even with this result, I am happy, and from now on, I will be all out selling “memory upgrade” to whomever Maximo users I meet.
An afterthought note: I used to consider DB2 a second choice for Maximo due to the difficulty of finding a good DB2 DBA, and thus, usually only suggested it to small clients with low budget. But now considering the significant cost of Enterprise version of Oracle or SQL if users want to implement this feature, the free bundled DB2 license offered with Maximo is an attractive option. For large enterprise client, I guess I will now present DB2 as an option for them to consider too.
For the last few years, SAP has been pushing hard on its HANA InMemory data platform and everybody talks about it. For me it makes sense because SAP’s ERP is such a huge system usually used by super large enterprises and is both a data intensive and mission critical system.
Maximo on the other hand is usually much less data intensive and for most clients I work with in Vietnam, they have small systems with databases of less than 10-20GB. Thus, I believe InMemory database is not a big deal for Maximo users. As I recently moved to Australia and got a chance to work with a much bigger client. Their Maximo runs on a cluster of more than two dozen JVMs yet somehow is still a bit slow considering the number of active users that they have. I suspect (since I don’t have visibility to their DB server) the bottle neck is the database in this case. Besides from the standard suggestions of looking at disk storage/SAN, network, memory allocation etc., I also mentioned they can consider implementing InMemory. Then I realized I never seen it implemented with Maximo, it would be a huge embarrassment if they look at it and find out that it doesn’t work.
This week I have some free time, so I decided to play around with InMemory database for Maximo to (1) confirm if it is possible and (2) see if it gives any real performance gain for Maximo.
Here is my system configuration:
Host laptop: Processor Core i7-6600U – 2 cores x 2.6 Ghz, 16GB RAM, SSD 500GB. Windows 7
VMWare: I gave it 10G Ram, 4 cores, Windows 7
Database: Oracle 12c R2 x64 Enterprise Edition. I gave it 1G for PGA, 4G for SGA (of which, 2G is given to INMEMORY store)
Maximo 7.6.0.0 – Demo database. I setup only one MXServer and gave it 2G heap size
As you can see, this is very different to a real production environment and thus the result found in this test may not reflect what you will find if implemented in production. Some key elements that I can think of that could lead to differences in results of this setup and real-world production system include:
Standard Maximo’s demo database is super small, less than 500MB. Thus, InMemory may not lead to any improvement at all
Maximo App and Database deployed on the same box. Thus, there’s no network latency between App and DB server as usually seen in production environment where DB server and App server are placed in two different subnets, and can have a firewall in between. This makes resource retrieval process much more expensive.
This has only one session instead of hundreds if not thousands of concurrent sessions as can be seen in production.
DB servers on production usually use superfast storage systems through SAN/RAID configuration, thus InMemory may not improve processing time in that case.
As mentioned, Maximo demo system is very small and most operations will complete almost instantly (less than .5 second). Thus, I decided to test two operations:
Generating Work Order from PM
Changing Work Order status
The data I chose is the Job Plan: “PMBULKTR – Bulk Trailer PM Servicing”, which applies to 5 trailers with Assetnum “44416x” (belong to ‘FLEET’ site). The reason I chose this job is because it has 70 tasks. It is a common problem for Maximo users when changing status of a Work Package with large number of child WO or tasks is that this operation is very resource intensive and can take a lot of time to complete. I have seen in many cases, such as in plant turn-around, changing WO status took so much time that the browser’s session timed out. So I decided to carry out a test following these steps: Select the 5 PMs, generate WO at once. Do it three times to measure the time it takes to complete. After I got 15 new WOs, I move to the Work Order Tracking app, and select all 15 of them, then try to change status to WAPPR, then to APPR, then WAPPR again to measure the time it takes each time.
After I finished timing the above steps, I will turn on INMEMORY for the whole ‘MAXIMO’ tablespace by issuing a command: ‘ALTER TABLESPACE maximo DEFAULT INMEMORY;’ Restart the system, then do the same test again to measure execution time with INMEMORY enabled.
Anyway, my expectation for this configuration would be a 2x to 5x in term of improved processing speed. The reason is when we built an add-on for inventory cataloguing, there was a process to compare technical specification of one item with the spec of thousands of other items to find similarity. This process took a lot of time to execute. The developer then cached the data in memory and run the operation with cached data only. This resulted in a boost of more than 100x in performance. So instead of hours, it takes only a few seconds to complete. Thus, I think an expectation of 2x to 5x performance gain in this case is reasonable.
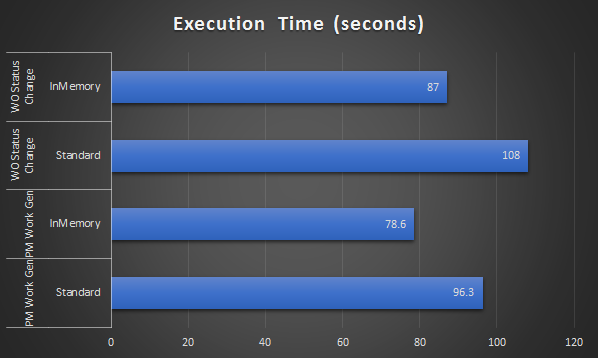
Below is the result I got from the test:
For each operation, I got only about 20% reduction in execution time. I tried a few other quick tests with other processes while switching on/off the INMEMORY feature and the result is consistent. Obviously with this result, my expectation of 2x – 5x improvement is proven to be unrealistic.
Thinking of putting this into practice, if your organization already have Oracle Enterprise Edition, setting up would be really simple. Throw in some extra bars of memory, select a few key tables that got queried the most such as the Work Order – related tables to populate them into INMEMORY area. If it can give you 20% reduction in execution time, I believe it is still very attractive to consider.
For Microsoft SQL Server, what I found on the web, we need SQL Server 2016 or 2017 Enterprise Edition which works with Maximo. (I tested installing Maximo 7.6.0.9 on SQL 2017 and it works well). The free Developer or Evaluation edition can also be used to test at home. However, I found the configuration steps seem to be more complex for Maximo as you have to review data structure to modify/exclude columns with specific datatypes such as XML, BLOB etc. Thus, if my company is using Maximo with SQL Server, I would think twice about implementing INMEMORY feature.
(Note: I don’t provide detailed steps to configure INMEMORY feature in Oracle 12c here because it is super simple, all you have to do is set INMEMORY_SIZE parameter to something other than 0 such as 2G or 4G. Make sure your SGA is larger than this, e.g. if INMEMORY_SIZE is 2G, SGA should be 3G or more. Otherwise, you will not be able to start the database service. Once INMEMORY_SIZE is allocated, issue the ALTER TABLESPACE or ALTER TABLE command to enable/populate the tablespace or table into INMEMORY area. Also make sure that you have Oracle 12c Enterprise Edition)
I am a freelance Maximo consultant based in Melbourne. If you enjoy reading my blog, please connect with me on LinkedIn to get updates on new posts. If you or your company need any professional assistance, please leave me a message, I'll call you back.