When upgrading Maximo or installing new add-ons or fix packs, new source files will be copied to SMP folder which include Java classes and DBC (database configuration) script files. After that, the installer will run the UpdateDB process to update the database, run the BuidMaximoEar process to build the EAR file, and then deploy the EAR file to Websphere.
The DBC script files contain incremental changes to the Maximo database which add changes to GUI, update data, and modify DB configuration objects. Most of the problems you get when installing fix packs or upgrading Maximo come from the UpdateDB process which execute these DBC files in a set order.
Thus, if you have a problem with this process, you can follow the below general steps to troubleshoot and fix the problem:
- When you have an error with UpdateDB process, note down the name of the log file that contains the error message. It has this format: [Process Name][YYYYMMDDhhmiss].log.
- If you have a problem with the UpdateDB process when running the installation program and don’t know the log file name, locate the [SMP]/maximo/tools/maximo folder and run the updatedb.bat (.sh) tool
again. It will produce the same error - Open the log file which is located under
[SMP]/maximo/tools/maximo/log folder to get the detailed error message. - Fix the problem then run the UpdateDB tool again from the command line. It will continue from the last success point.
Following is an example on how I got a problem when trying to create a demo database from an SMP copy I received from my client just a few hours ago. When installing demo instance by executing maxinst.bat, Maximo will create a standard initial database by running a bunch of SQL statement from [SMP]/maximo/tools/maximo/en/maxdemo.ora for Oracle (or maxdemo.db2, or maxdemo.sqs for DB2 and SQL Server respectively). Then it will call the UpdateDB process to apply incremental changes to this database to install add-ons/fix packs which are already installed in this SMP folder).
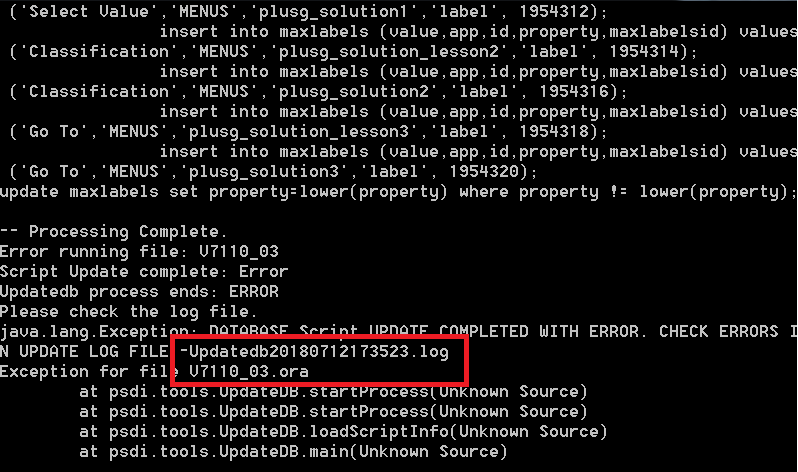
During this process, I got the follow error:
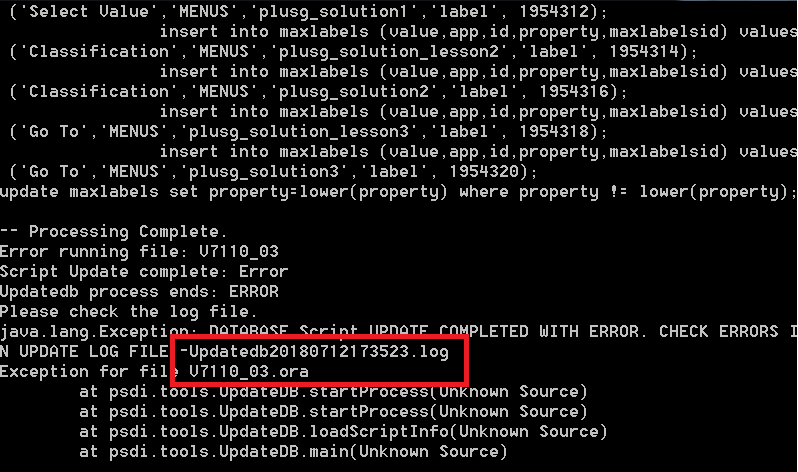
To get more details about the error, I locate the Updatedb20180712173523.log in folder: [SMP]/maximo/tools/maximo/log. It gives me more details about the problem:
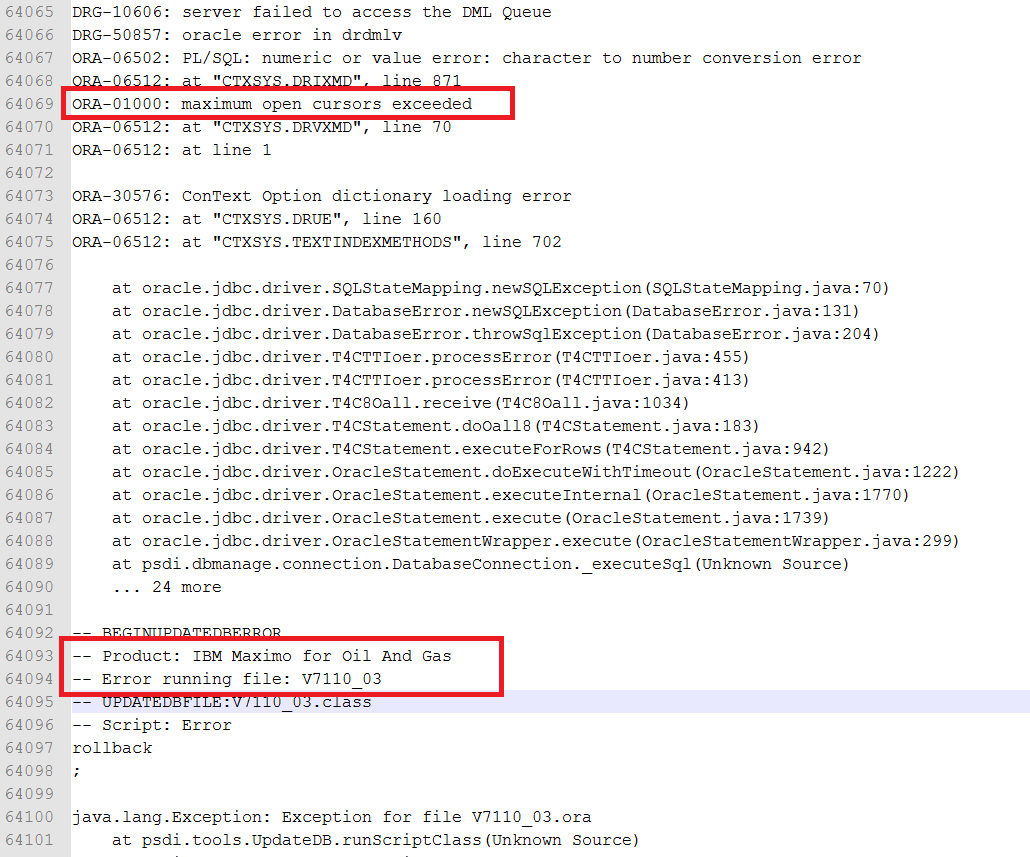
The problem occurred while it tried to execute the file V7110_03 script for the Oil & Gas add-on. In this case, if I scrolled up several lines, I can quickly see the problem, which is caused by an ORA-01000 – maximum open cursors exceeded. Basically, I forgot to set open_cursors parameter to 1000 as recommended by IBM, leaving it with default value = 300 when creating a new database. Thus, all I have to do in this case is increase it to 1000, then run the UpdateDB tool again. With real production database, sometimes I have to increase it to 5000 or 10000 in order to apply some fix packs.
In many cases, the problem is not easily identified by just looking at this log file. So we have to scroll up to a bit further, to identify which statement is causing the issue. Then, we will have to open the DBC script file which can be found under [SMP]/maximo/tools/maximo/en/[add-on folder]/[dbc script file]. For example, in this case, it is …/en/oilandgas/V7110_03.ora
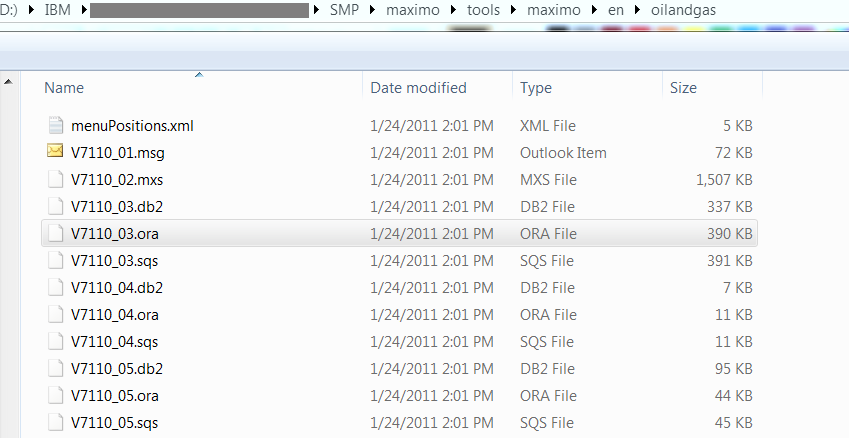
There are a number of script file types:
- Files with .ora, .sqs, .db2 extensions: are just normal SQL files applicable for Oracle, SQL Server, and DB2 respectively. You can run the SQL statement from this file against the database to check for problems directly.
- Files with .msg extension: are used to
add/modify existing messages. You normally don’t have a problem with these. - Files with .mxs, and .dbc extensions: are used to
modify application GUI design, and apply data updates or database
configuration changes.
Most of the problems come from .dbc files. To understand DBC script and identify what each statement does, you can refer to this DBC XML Format Technical Reference
Some common problems we have when running UpdateDB include:
- Error when creating a unique index: in this
case, we have to query and update the data to remove or fix records with
duplicated keys - Error when creating existing objects: most of the
time, we can drop the existing object as a new object will be created by the
script anyway - Missing script files, or script file doesn’t follow naming convention, which have ordered number. If there’s a missing script file, you can create an empty file by copy/paste from an existing dbc file, and rename it to have a missing ordered number. For files which don’t follow naming convention, I got get this java.lang.ClassCastExeption a few times when updatedb with Linear add-on, turns out there is a file named V7500_linear.dbc which updatedb expects to have a number after V7500, so all I have to do is change it to V7500_02.dbc and it doesn’t complain any more
- DB operation fails due to maximum open_cursors or processes exceeded (in Oracle): increase the open_cursors, processes parameter and try to run UpdateDB again.
- Java NullPointerException: this one is quite difficult to figure out. We have to look at the DBC file to understand what it’s trying to do. This is often caused by bad data, such as orphan records referencing a non-existence parent.
- Error with certain DB operations like when it is unable to create a new Workorder table after Drop the table (when there’s a change to the table
structure): I’m not exactly sure what mechanism causes this, but I found the
problem goes way if I run the UpdateDB process again (and again). I only
attempt to fix it if the problem persists after the 3rd run.
I hope this helps you when the going gets tough.