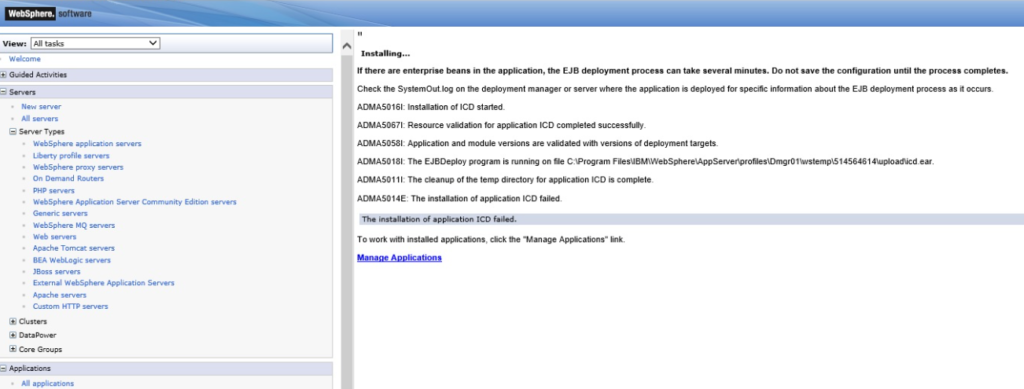
OutOfMemory error when deploying Maximo in Websphere
This post describes how to update WebSphere settings to address the Out-Of-Memory error when deploying a big maximo.ear file
This post describes how to update WebSphere settings to address the Out-Of-Memory error when deploying a big maximo.ear file
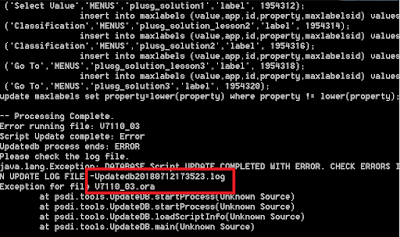
When upgrading Maximo or installing new add-ons or fix packs, new source files will be copied to the SMP folder
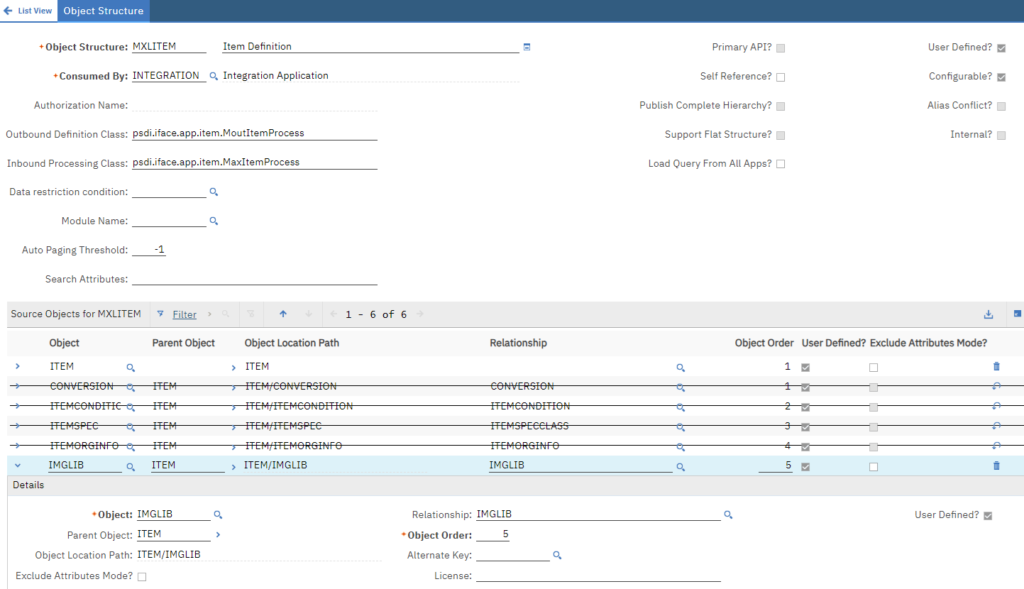
We can enable import/export of binary data with automation script. Below is how to configure Maximo 7.6 to bulk upload images to Item Master application
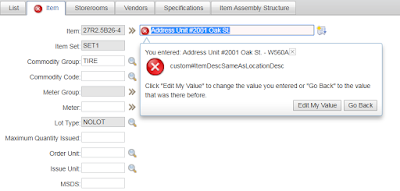
Sometimes in our application, we need to build custom services that run when Maximo starts. We can extend the psdi.server.AppService

I recently had to look at ways to improve the performance of a custom-built operation in Maximo. Essentially, it is
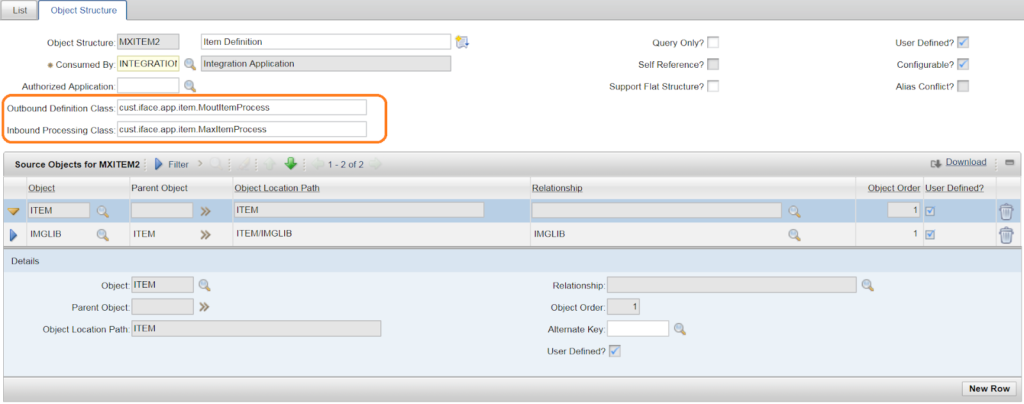
In Maximo, we can upload images as attachments (DOCLINKS) which are stored as files on the server or as “profile”
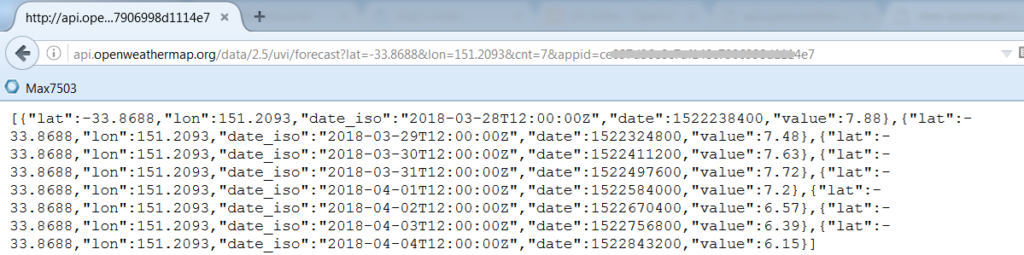
Federated MBO allows you to link an API from an external system and make it looks like a standard object in Maximo and treat it like other standard Maximo objects
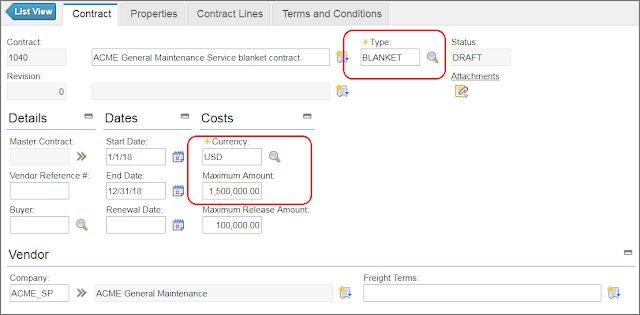
A friend of mine who has experience with SAP asked whether Maximo can handle a “Blanket PO” process similar to
In previous posts, we have practised how to create a JSP page, register it as a component, and register a