For the past few years, SAP has been pushing hard on its HANA InMemory data platform and everybody talks about it. For me, it makes sense because SAP’s ERP is such a huge system usually used by super-large enterprises. It is both a data-intensive and mission-critical system.
Maximo on the other hand is usually much less data-intensive. Most clients I work with in Vietnam have small systems with databases of less than 10-20GB. Thus, I believe InMemory database is not a big deal for Maximo users. As I recently moved to Australia and had a chance to work with a much bigger client. Their Maximo runs on a cluster of more than two dozen JVMs yet somehow is still a bit slow considering the number of active users they have. I suspect (since I don’t have visibility to their DB server) the bottleneck is the database in this case. Besides the standard suggestions of looking at disk storage/SAN, network, memory allocation etc., I also mentioned they can consider implementing InMemory. Then I realized I had never seen it implemented with Maximo, it would be a huge embarrassment if they looked at it and found out that it doesn’t work.
This week I have some free time, so I decided to play around with InMemory database for Maximo to (1) confirm if it is possible and (2) see if it gives any real performance gain for Maximo.
Below is my system configuration:
- Host laptop: Processor Core i7-6600U – 2 cores x
2.6 Ghz, 16GB RAM, SSD 500GB. Windows 7 - VMWare: I gave it 10G Ram, 4 cores, Windows 7
- Database: Oracle 12c R2 x64 Enterprise Edition.
I gave it 1G for PGA, 4G for SGA (of which, 2G is given to INMEMORY store) - Maximo 7.6.0.0 – Demo database. I setup only one
MXServer and gave it 2G heap size
As you can see, this is very different to a real production
environment and thus the result found in this test may not reflect what you will
find if implemented in production. Some key elements that I can think of that
could lead to differences in results of this setup and real-world production
system include:
- Standard Maximo’s demo database is super small,
less than 500MB. Thus, InMemory may not lead to any improvement at all - Maximo App and Database deployed on the same box. Thus, there’s no network latency between App and DB server as usually seen in the production environment where the DB server and App server are placed in two different subnets, and can have a firewall in between. This makes the resource retrieval process much more expensive.
- This has only one session instead of hundreds if not thousands of concurrent sessions as can be seen in production.
- DB servers on production usually use superfast storage systems through SAN/RAID configuration, thus InMemory may not improve processing time in that case.
As mentioned, Maximo demo system is very small and most
operations will complete almost instantly (less than .5 second). Thus, I
decided to test two operations:
- Generating Work Order from PM
- Changing Work Order status
The data I chose is the Job Plan: “PMBULKTR – Bulk Trailer PM Servicing”, which applies to 5 trailers with Assetnum “44416x” (belong to ‘FLEET’ site). The reason I chose this job is because it has 70 tasks. It is a common problem for Maximo users when changing the status of a Work Package with large number of child WO or tasks is that this operation is very resource-intensive and can take a lot of time to complete. I have seen in many cases, such as in plant turn-around, changing WO status took so much time that the browser’s session timed out. So I decided to carry out a test following these steps: Select the 5 PMs, and generate WO at once. Do it three times to measure the time it takes to complete. After I got 15 new WOs, I moved to the Work Order Tracking app, and selected all 15 of them, then tried to change the status to WAPPR, then to APPR, and then WAPPR again to measure the time it takes each time.
After I finished timing the above steps, I will turn on INMEMORY for the whole ‘MAXIMO’ tablespace by issuing a command: ‘ALTER TABLESPACE maximo DEFAULT INMEMORY;’ Restart the system, then do the same test again to measure execution time with INMEMORY enabled.
Anyway, my expectation for this configuration would be 2x to 5x in terms of improved processing speed. The reason is when we built an add-on for inventory cataloguing, there was a process to compare the technical specifications of one item with the specs of thousands of other items to find similarities. This process took a lot of time to execute. The developer then cached the data in memory and ran the operation with cached data only. This resulted in a boost of more than 100x in performance. So instead of hours, it takes only a few seconds
to complete. Thus, I think an expectation of 2x to 5x performance gain in this case is reasonable.
Below is the result I got from the test:
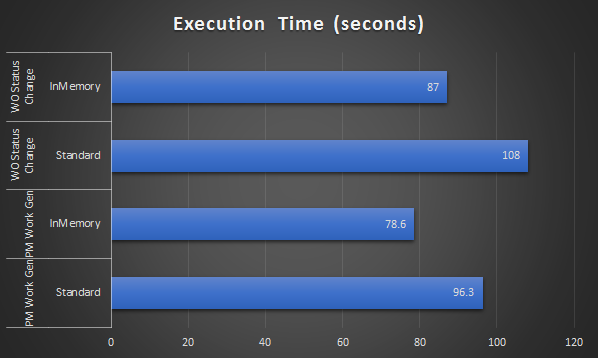
For each operation, I got only about 20 per cent reduction in execution time. I tried a few other quick tests with other processes while switching on/off the INMEMORY feature and the result is consistent. Obviously, with this result, my expectation of 2x – 5x improvement is proven to be
unrealistic.
Thinking of putting this into practice, if your organization already have Oracle Enterprise Edition, setting up would be really simple. Throw in some extra bars of memory, and choose a few key tables that got queried the most such as the tables related to Work Order to populate them into INMEMORY area. If it can give you 20% reduction in execution time, I believe it is still
very attractive to consider.
For Microsoft SQL Server, what I found on the web, we need SQL Server 2016 or 2017 Enterprise Edition which works with Maximo. (I tested installing Maximo 7.6.0.9 on SQL 2017 and it works well). The free Developer or Evaluation edition can also be used to test at home. However, I found the configuration steps seem to be more complex for Maximo as you have to review data structure to modify/exclude columns with specific datatypes such as XML, BLOB etc. Thus, if my company is using Maximo with SQL Server, I would think twice about implementing INMEMORY feature.
Note: I don’t provide detailed steps to configure INMEMORY feature in Oracle 12c here because it is super simple, all you have to do is set INMEMORY_SIZE parameter to something other than 0 such as 2G or 4G. Make sure your SGA is larger than this, e.g. if INMEMORY_SIZE is 2G, SGA should be 3G or more. Otherwise, you will not be able to start the database service. Once INMEMORY_SIZE is allocated, issue the ALTER TABLESPACE or ALTER TABLE command
to enable/populate the tablespace or table into INMEMORY area. Also, make sure that
you have Oracle 12c Enterprise Edition)

 – Huge Performance Gain")

