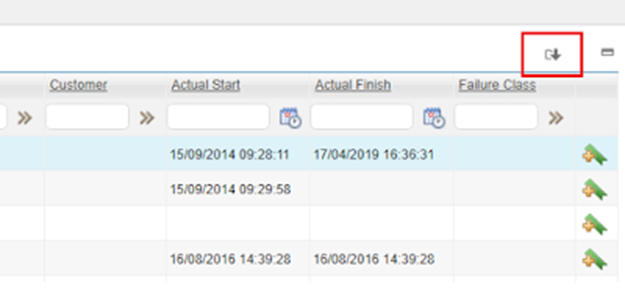
The performance effect of the Download button in Maximo
Discussion about the Download table data button in Maximo causes poor performance to the application and even crashes the server.
Discussion about the Download table data button in Maximo causes poor performance to the application and even crashes the server.

This article describes my experience troubleshooting a massive degradation of Maximo performance after installation of some add-ons and upgrading Maximo.
Sometimes in our application, we need to build custom services that run when Maximo starts. We can extend the psdi.server.AppService

I recently had to look at ways to improve the performance of a custom-built operation in Maximo. Essentially, it is
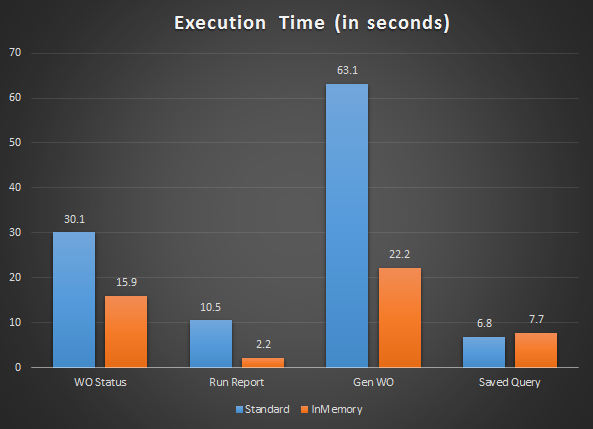
Last week, I played around with Oracle’s new toy: the InMemory feature available in Enterprise Edition. Although it made Maximo
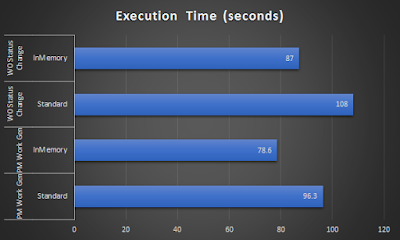
For the past few years, SAP has been pushing hard on its HANA InMemory data platform and everybody talks about