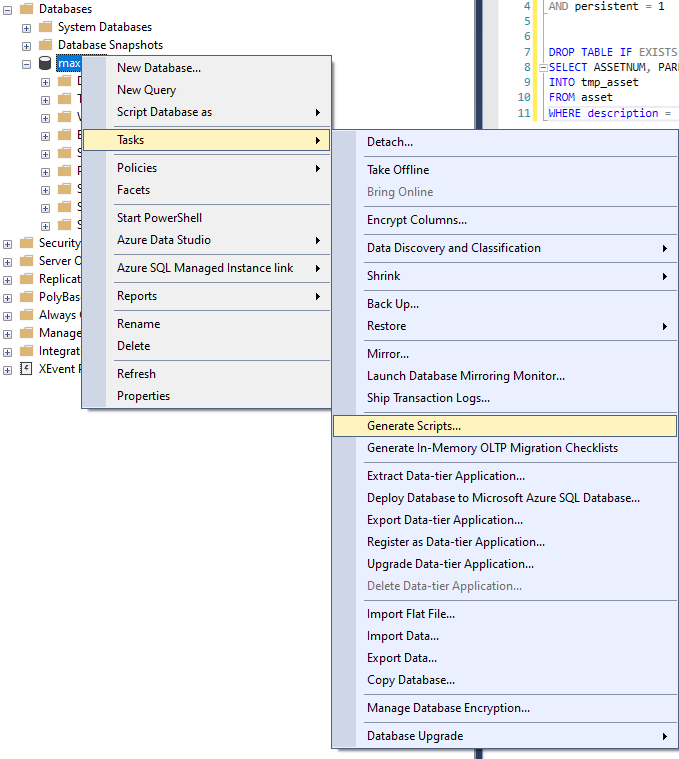
How to generate INSERT script for Maximo data with SQL Server?
When dealing with a large amount of data or migrating workflow configuration, we might need to generate and use INSERT script. This article describes how to do it.
When dealing with a large amount of data or migrating workflow configuration, we might need to generate and use INSERT script. This article describes how to do it.
With the introduction of the Maximo Application Suite, I have had to deal with more and more Maximo environments on
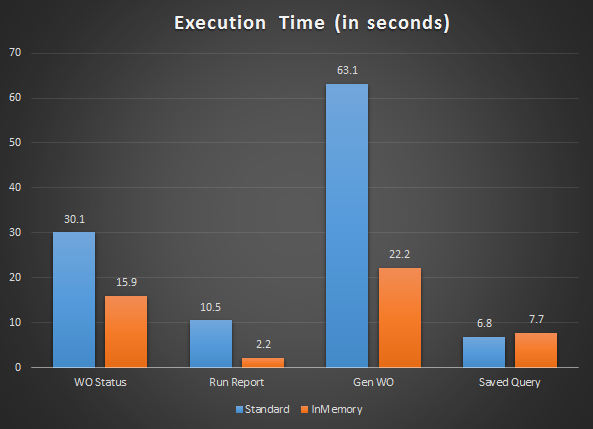
Last week, I played around with Oracle’s new toy: the InMemory feature available in Enterprise Edition. Although it made Maximo
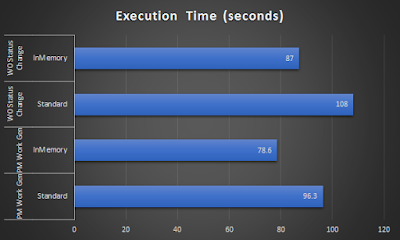
For the past few years, SAP has been pushing hard on its HANA InMemory data platform and everybody talks about