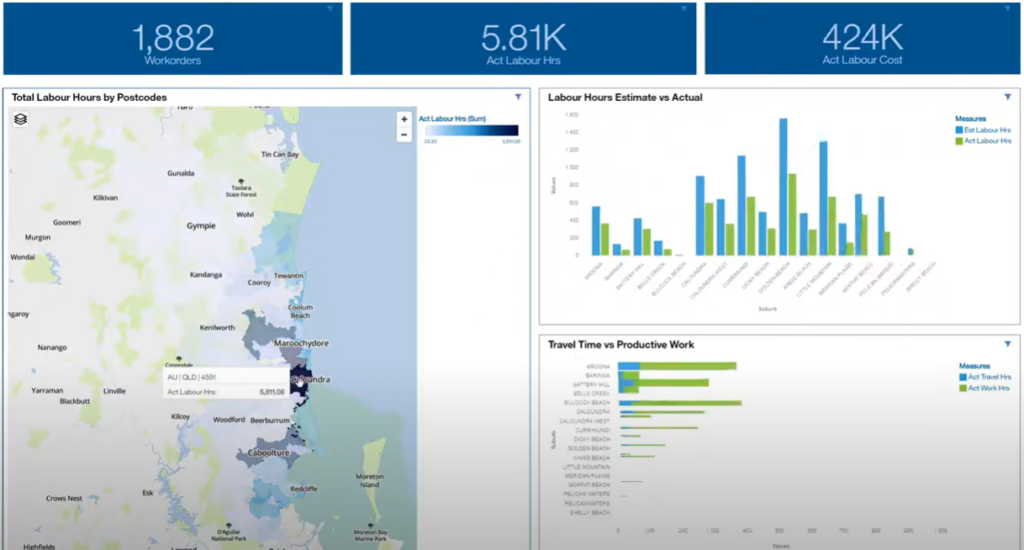
Play around with Map control in Cognos Analytics
There’s been quite a bit of talk recently on the web about the new partnership with MapBox to deliver new […]
There’s been quite a bit of talk recently on the web about the new partnership with MapBox to deliver new […]
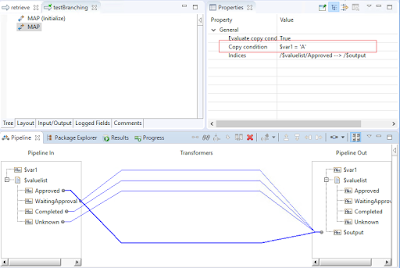
Conditional Logic is the most important building block of any software development tool. WebMethods is not a programming language, but
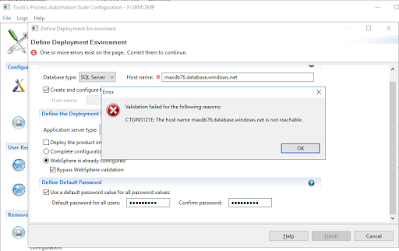
Recently, I started playing with Azure by attempting to migrate a Maximo instance from my local VM to Azure platform.
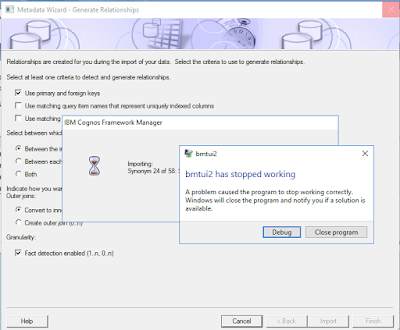
I tried to create a new Framework Manager project to build a package in which I will join some big
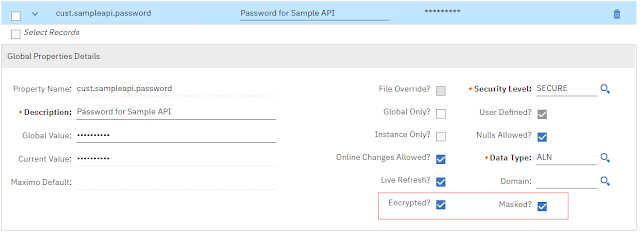
This article describes a little trick to display a masked and encrypted value stored in Maximo’s System Properties. This is often necessary when the legacy system is handed over without documentation.
Last week, while attending a call to discuss an integration interface between Maximo and an Azure SQL database, the other
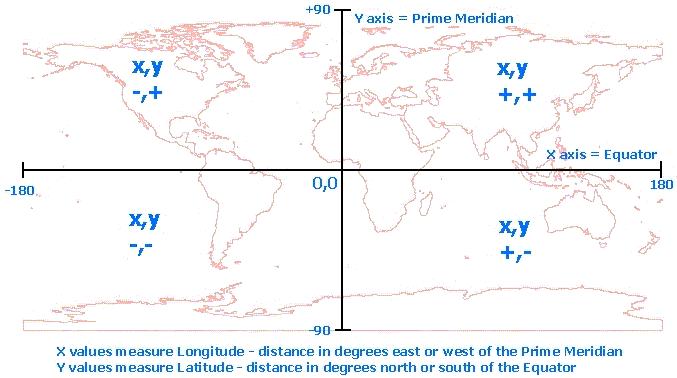
As I play around with the Cognos Analytics map controls, it appears to me it only understands Latitude/Longitude values, but

Working with Maximo, perhaps we all have the same frustration with the constant changes by IBM marketing team who work
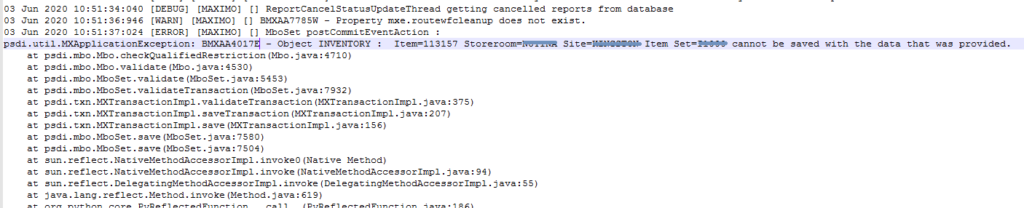
This article talks about the “BMXAA4017E – object cannot be saved” error in Maximo due to using the wrong user profile when fetching an MboSet using MXServer