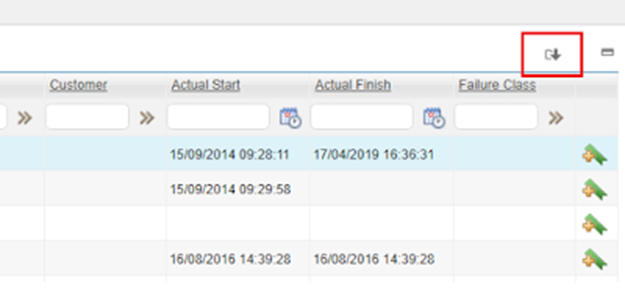
The performance effect of the Download button in Maximo
Discussion about the Download table data button in Maximo causes poor performance to the application and even crashes the server.
Discussion about the Download table data button in Maximo causes poor performance to the application and even crashes the server.

Working in IT, we deal with strange issues all the time. However, every once in a while, something would come

Downtime is costly to the business. As developers, avoiding it can give us a ton of benefits both in terms
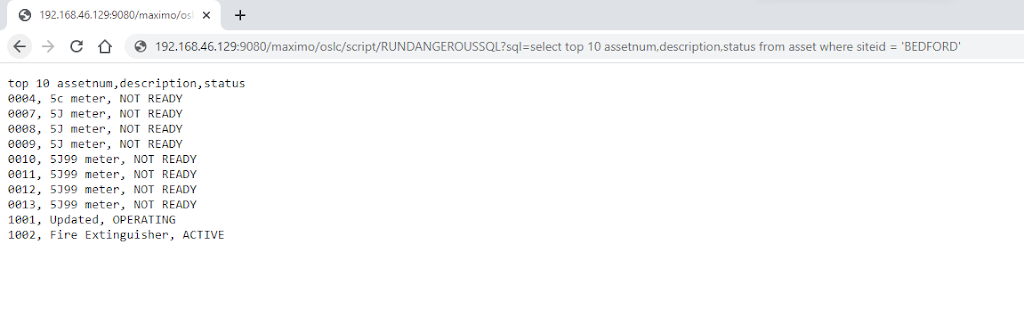
With the introduction of the Maximo Application Suite, I have had to deal with more and more Maximo environments on
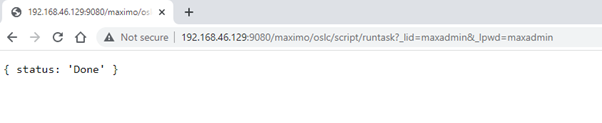
One error we often have to deal with is an incorrect sequence when adding new data to Maximo. There are
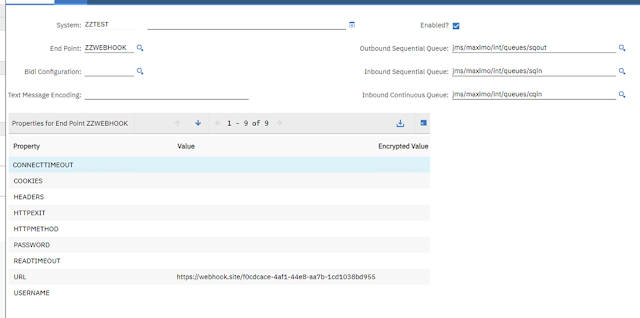
While the JSON API in the newer version of Maximo is quite useful, for many integration scenarios, I still prefer
This issue hit me a few times and always took me some time to figure out what happened. So I

It took me some time to get to this piece of code, but requirement changed and I needed to ditch

Just a bunch of my personal notes about Maximo attachment (DOCLINKS) In summary, I usually hit with issues with doclinks